
What's Order-Preserve RAG (OP-RAG)?
Why use RAG in the Era of Long-Context Language Models? Part 2

In recent years, the field of natural language processing has seen remarkable advancements, particularly in the development of large language models (LLMs) with increasingly expansive context windows. Last week we introduced the research from Li et al. (2024) comparing RAG with and without long-context (LC) LLMs.
Today, we’ll delve into another intriguing paper by Nvidia researchers, "In Defense of RAG in the Era of Long-Context Language Models." Interestingly, this paper presents a contrasting conclusion: using a proposed mechanism, RAG outperforms models that rely solely on long-context LLMs in delivering higher-quality answers.
The issue
Despite the impressive capabilities of long-context LLMs, there are inherent limitations to processing extremely large amounts of text in a single pass. As the context window expands, the model's ability to focus on relevant information can diminish, potentially leading to a degradation in answer quality. This phenomenon highlights a critical trade-off between the breadth of available information and the precision of the model's output.
P.S. We have also previously covered this in this post:
The Loss-in-the-Middle Problem in RAG🙀

Did you know that as smart as advanced models like GPT, when faced with questions involving extensive context, can sometimes struggle to provide accurate responses?
Order-Preserve RAG (OP-RAG)
In light of these challenges, researchers have proposed a novel approach called Order-Preserve Retrieval-Augmented Generation (OP-RAG). This method aims to combine the strengths of both RAG and long-context LLMs while mitigating their respective weaknesses.
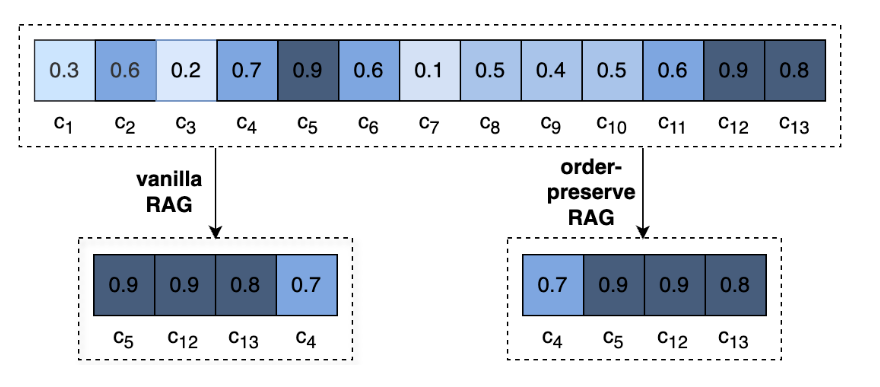
The key idea of OP-RAG lies in its preservation of the original order of retrieved chunks from the source document. Unlike traditional RAG, which typically arranges retrieved chunks by relevance, OP-RAG maintains the sequential structure of the original text. This approach has shown significant improvements in answer quality, particularly when dealing with a large number of retrieved chunks.
At first, this might seem counterintuitive. However, upon further reflection, it makes sense—it also preserves the logical flow of the original content.
The Inverted U-Shaped Curve: Finding the Sweet Spot
Keep reading with a 7-day free trial
Subscribe to The MLnotes Newsletter to keep reading this post and get 7 days of free access to the full post archives.