
The Harness Beats the Model: Demystifying Agent Harness Engineering


Over the past couple of years, I have spent most of my working hours building agent systems in production, multi-agent pipelines for enterprise clients, agentic platforms for startups, and educational content for a community of over 100,000 people learning to work with LLMs. Across all of that work, one pattern kept showing up: the teams that shipped reliable, autonomous agents were not the ones with the biggest models. They were the ones who had thought hardest about the infrastructure wrapped around those models.
That observation is the starting point for this series. Over the next few posts, I want to share what I have learned from the ground up about agent harness engineering, the discipline of building the execution environment, safety rails, and feedback loops that turn a raw LLM into a system you can actually trust. Each post will move from concepts to concrete code, so whether you are just getting started with agents or already shipping them to production, there will be something here for you.
This is Part 1. Let’s start with the most important question: what even is a harness, and why does it matter more than the model inside it?
If you have been building with LLMs over the last couple of years, you have likely participated in two distinct waves of optimization:
Prompt Engineering: Writing carefully crafted instructions, system prompts, and few-shot examples to make a model output the correct format.
Context Engineering: Building retrieval-augmented generation (RAG) pipelines, managing vector databases, and injecting relevant context at the exact right time.
But as we pivot toward fully autonomous AI systems, agents that can write code, manage filesystems, and execute workflows over several hours, we are hitting the limits of prompts and context alone.
Today, a third wave has taken center stage: Harness Engineering.
The core realization of this era is simple: An LLM is not an agent. An LLM is a reasoning engine. To make that engine do useful work safely, repeatably, and autonomously, we must surround it with software.
In the developer community, a new rule of thumb has emerged: “If you’re not the model, you’re the harness.”
In this post, we will demystify what an agent harness actually is, why it holds more leverage than the underlying model weights, and how you should think about building one.
The Metaphor: The Engine vs. The Car
To understand why a harness is necessary, consider a high-performance sports car engine.
If you bolt a 600-horsepower engine to a wooden pallet in your garage and turn it on, you do not have a vehicle. You have a loud, vibrating hazard that will quickly burn through its fuel or damage itself. To make that engine useful, you need a chassis, a steering column, brakes, a dashboard, a fuel pump, and a seatbelt

In the AI agent stack:
The LLM is the engine. It provides raw reasoning, language processing, and planning capabilities.
The Harness is the car. It is every piece of code, configuration, filesystem access, state management, and execution logic wrapped around that model.
Without the harness, a model cannot safely write a file, execute a test, or recover from a compile error. The harness is what turns static, one-shot token generation into dynamic, continuous action.
What Lives Inside an Agent Harness?
By definition, the harness is the entire software ecosystem built to constrain, guide, and support the LLM. If we look under the hood of modern agent runtimes (like Claude Code or LangChain’s Deep Agents), a standard harness typically provides several core services:
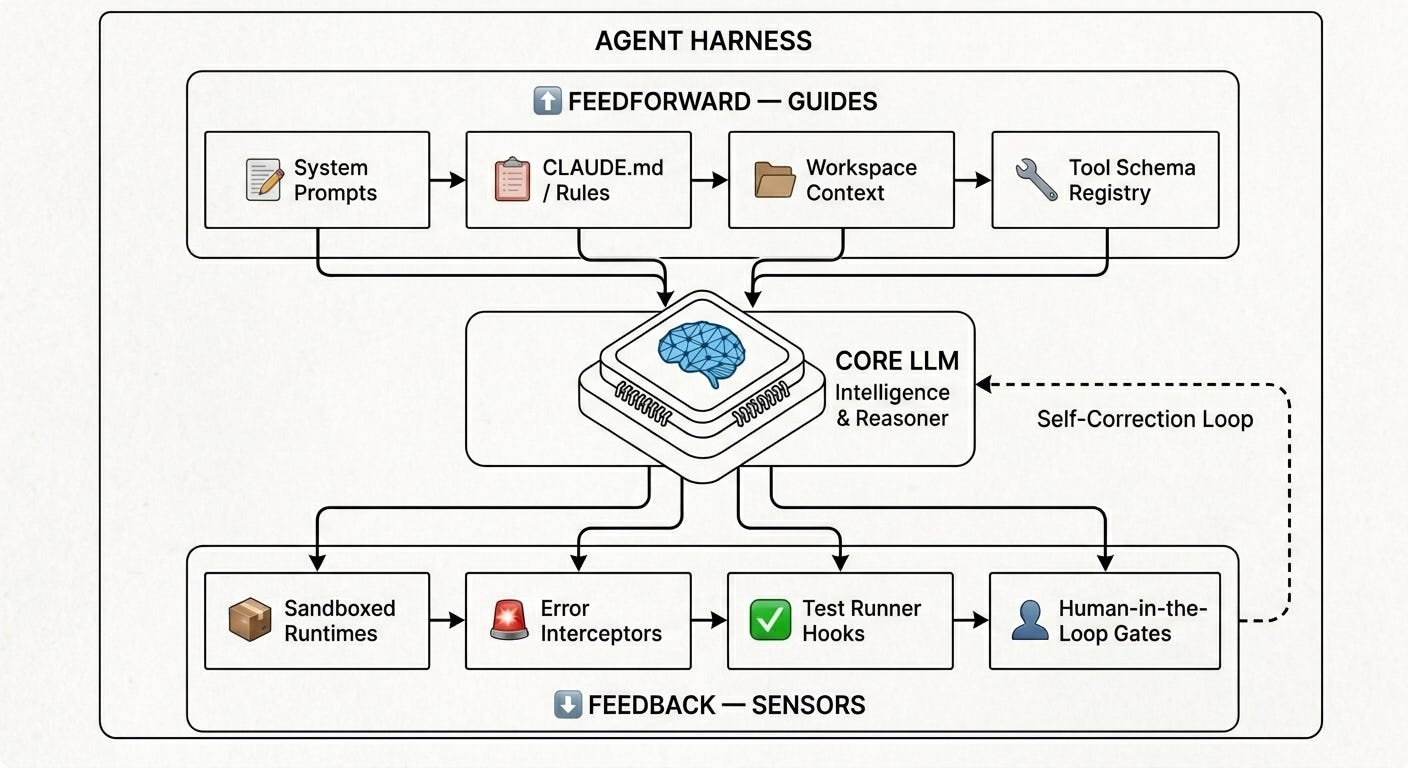
The Execution Loop: The basic state machine (
while active: run_step()) that keeps the agent iterating toward its goal.Context Compaction: Programmatic logic that summarizes historical messages, archives oversized tool outputs, and manages the model’s memory limits over long-running sessions.
The Sandbox: A secure, isolated runtime (like a Docker container or microVM) where the agent can run bash commands or execute code without compromising your local machine.
Lifecycle Hooks: Code that intercepts the agent’s actions before or after they execute (e.g., checking code with a linter before running a compiler).
Human-in-the-Loop Gates: Permission layers that halt execution and ask a human to approve potentially destructive commands (e.g., deleting a folder or executing a database write).
The Core Paradigm: Feedforward vs. Feedback
A useful way to think about how a harness works is to divide its responsibilities into two major systems: Feedforward Controls (Guides) and Feedback Controls (Sensors).
1. Feedforward: Setting the Rails Before the Model Acts
Feedforward mechanisms set the model up for success before it generates a single token. This includes:
System Prompt Assembly: Dynamically constructing the prompt based on the agent’s current workspace.
Project-Level Rules: Injecting repository-specific guidelines (often read from files like
CLAUDE.mdorAGENTS.md) directly into the agent’s memory to prevent common style or architectural mistakes.
2. Feedback: Reacting After the Model Acts
Feedback mechanisms are where the harness truly shines. Instead of forcing a human to read every error, the harness acts as a sensor.
The Self-Correction Loop: If the agent writes bad code, the harness attempts to compile it, catches the syntax error, and passes that error back to the model as a new message: “Here is the compiler output; please fix this syntax error.”
By automating this “sensor-loop”, the agent corrects its own mistakes in the background, only surfacing to the human user once a clean, verified solution is found.
Harness vs. Orchestration Framework: What’s the Difference?
A common point of confusion is how a harness differs from existing orchestration libraries like LangChain or LangGraph.
An Orchestration Framework is a toolbox. It provides the building blocks—the graph runtimes, the token counters, the schema definitions—needed to connect models to code.
An Agent Harness is an opinionated, batteries-included application wrapper built with those blocks. It dictates exactly how files are read, how sandboxes are managed, how memory is pruned, and how users approve tasks.
You use a framework to build a harness. Your harness is the custom, end-to-end environment that handles your business logic.
The Real Leverage: The Harness Beats the Model
When an agent fails a complex coding benchmark, developers are often tempted to blame the underlying model. The standard response is to wait for the next, larger model to release.
However, the practical evidence points in a clear direction: tuning the harness is often more effective than upgrading the model.
The SWE-bench leaderboard, the industry benchmark for autonomous coding agents, illustrates this well. Teams that reached the top did not do it by swapping in a bigger model. They did it by obsessing over the harness: how errors were formatted before being fed back, how long context was pruned, how the agent was given permission to retry. The same model weights, run inside a smarter harness, produced dramatically better results.
This is the Harness Engineering Mindset. Every time an agent makes a mistake, do not just tweak your system prompt. Instead, ask: What sensor, sandbox rule, or execution hook could I add to my harness so the system prevents or self-corrects this mistake next time?
What’s Next?
Now that we have established the “what” and “why” of the agent harness, it’s time to look at how these systems are built.
In Part 2 of this series, we will zoom in and examine the Anatomy of a Modern Agent Harness. We will sketch out a minimal Python implementation of an agent loop, look at how to build a simple tool registry, and write code that captures execution errors to feed them back into the model.
Have you started building custom wrappers around your LLMs? What constraints or feedback loops have made the biggest difference in your projects? Let’s discuss in the comments below.