
Knowledge Graphs Needed an AI Layer. So I Built One


I’ve been working with semantic web technologies since 2012. RDF, OWL, SPARQL, Protege, Jena, triplestores -- these have been part of my toolkit for over a decade. I’ve built ontologies for research projects, designed knowledge graphs for NLP pipelines, and written more SPARQL than I’d care to admit.
And throughout all of it, one frustration has remained constant: the gap between what knowledge graphs can do and what people are willing to put up with to use them.
The technology is sound. The W3C stack is well-designed. Ontological reasoning is genuinely powerful. But the barrier to entry has always been too high. You need to understand RDF serialization, SPARQL syntax, OWL semantics, URI design, and named graph management before you can do anything useful. For most teams, the learning curve kills adoption before the value becomes visible.
LLMs have finally given us the tools to close that gap. So I built KeplAI -- an open-source platform that puts an AI layer on top of the standards-based semantic web stack, making knowledge graphs accessible without sacrificing the rigor that makes them worth using in the first place.
The Semantic Web’s Adoption Problem
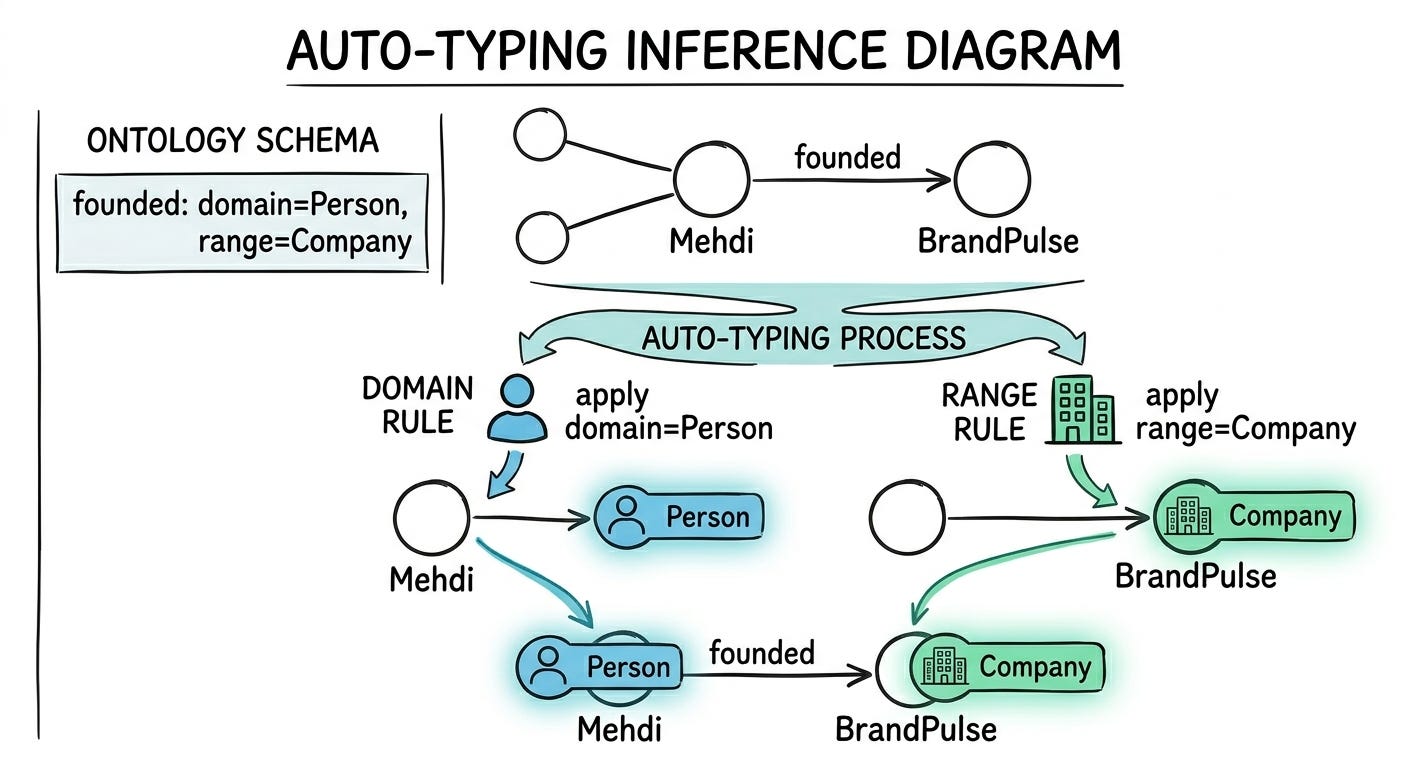
If you’ve worked with knowledge graphs, you know this story. You show someone a beautifully reasoned inference chain -- how (Mehdi, founded, BrandPulse) plus the ontology’s domain/range constraints automatically infers that Mehdi is a Person and BrandPulse is a Company. They’re impressed. Then you show them the SPARQL they’d need to write to query it, and their eyes glaze over.
The semantic web has always had a marketing problem disguised as a usability problem. The underlying ideas -- triples, ontologies, inference, linked data -- are elegant. But the tooling has historically assumed that everyone using it has a PhD in knowledge representation.
I don’t think the answer is to dumb it down. Stripping away the ontology layer to make things “simpler” defeats the purpose. Without formal semantics, you just have a labeled property graph -- fine for some use cases, but you lose inference, auto-typing, and schema validation. You lose the reason knowledge graphs are more powerful than a relational database in the first place.
The answer is to keep the semantic rigor underneath and put a natural-language interface on top.

What Knowledge Graphs Actually Give You
For readers who haven’t worked with these technologies before, let me explain why anyone would bother with all this machinery instead of just using a regular database.
A knowledge graph stores facts as triples: subject, predicate, object.
(Mehdi, founded, BrandPulse)
(BrandPulse, industry, AI)
(Alice, worksAt, BrandPulse)Each triple is a fact. Together, they form a graph you can traverse. Want to know who works at companies Mehdi founded? Follow the edges. No JOINs, no pre-designed queries, no schema migration when you add a new relationship type.
But the real power comes from ontologies -- formal descriptions of what types of things exist and how they can relate.
Why Ontologies Matter
An ontology doesn’t just describe data. It enables reasoning.
Define this:
Class: Person
Class: Company
Property: founded (domain: Person, range: Company)Now when someone adds (Mehdi, founded, BrandPulse), the system automatically infers that Mehdi is a Person and BrandPulse is a Company. This is called auto-typing, and after working with it for over a decade, I can tell you it’s one of those capabilities that seems minor until you realize how much manual annotation it eliminates at scale.
Ontologies also give you constraint validation (is this triple even valid given the schema?), cross-domain reasoning (if a Person can found a Company, and a Company has Employees, what can we infer about the relationship between founders and employees?), and interoperability (your ontology and mine can be linked through shared upper ontologies).
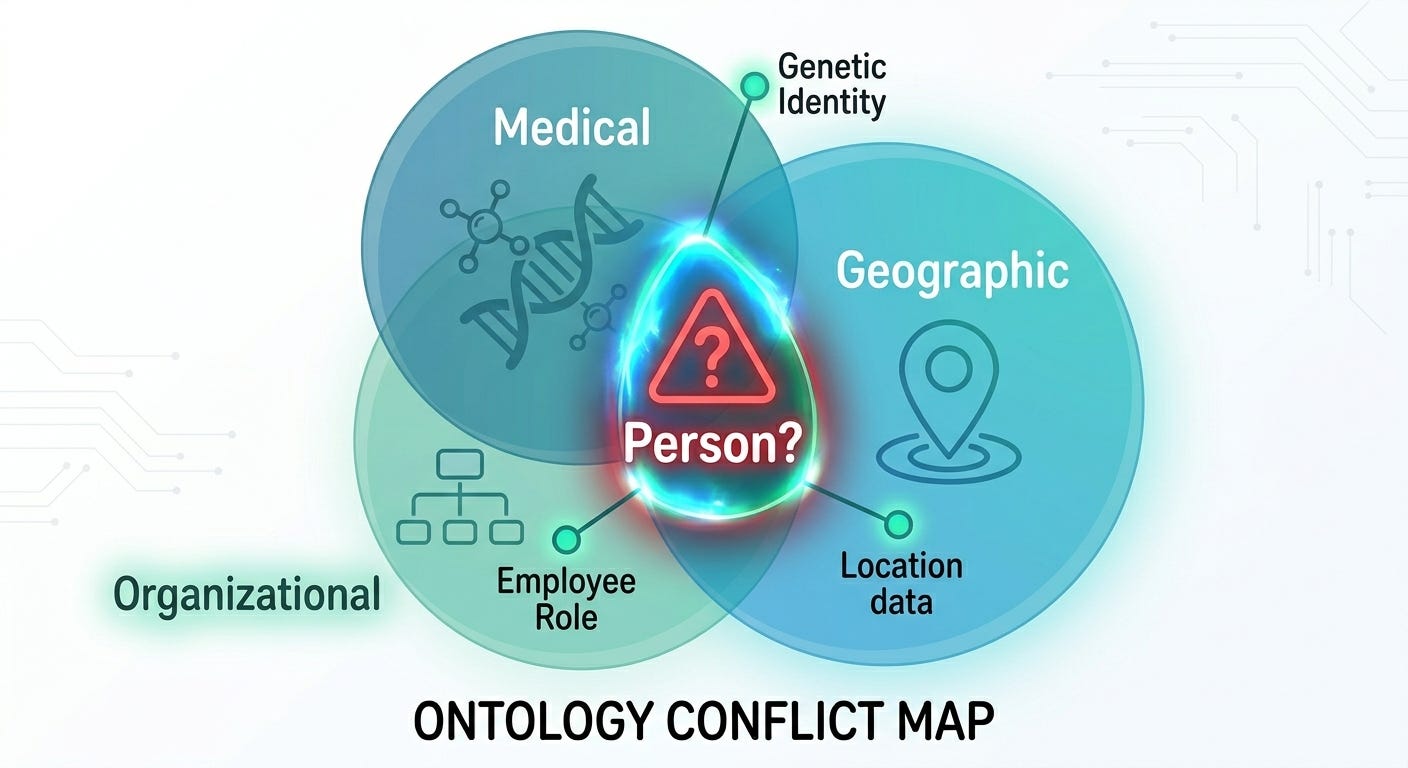
The Multi-Ontology Problem
Real-world knowledge doesn’t fit into one neat schema. This is something I’ve dealt with repeatedly across projects. A hospital needs a medical ontology, an organizational one, and a geographic one. A research lab might combine domain-specific ontologies with FOAF, Dublin Core, and Schema.org.
These ontologies overlap. Both FOAF and Schema.org define “Person.” When your data says “Person,” which one do you mean? When two ontologies define different properties with the same label, which takes precedence?
In KeplAI, each imported ontology lives in its own named graph inside Apache Jena Fuseki. URI resolution searches across all loaded ontologies. If there’s a unique match, it resolves. If two ontologies claim the same label, the system raises a conflict rather than silently picking one. This is the kind of design decision that comes from having been burned by silent ontology collisions more than once.
What LLMs Finally Make Possible
I’ve watched the semantic web community struggle with two problems for years. LLMs don’t solve them perfectly, but they solve them well enough to fundamentally change the equation.
Populating the Graph
Knowledge graph construction has always been the bottleneck. I’ve used every approach:
Manual curation -- accurate but impossibly slow. I’ve spent weeks annotating corpora for research projects that produced graphs with a few thousand triples.
Rule-based extraction -- fragile. Change the sentence structure and your regex pipeline breaks.
Supervised NER/RE models -- requires labeled training data, which requires... manual curation. A chicken-and-egg problem.
LLMs break this cycle. Give GPT-4 a paragraph and an ontology schema, and it extracts structured triples that actually conform to the schema:
triples = await kg.extract_and_store(
"Mehdi founded BrandPulse in 2024. The company focuses on AI.",
mode="strict" # Constrained to ontology schema
)In “strict” mode, extraction is constrained to properties defined in your ontology -- the LLM can only produce triples that match your schema. In “open” mode, it discovers relationships freely, which is useful for exploratory graph building.
But extraction alone isn’t enough. Text says “M. Allahyari” and the graph already has “Mehdi Allahyari” -- are they the same entity? This entity disambiguation problem is something I’ve worked on extensively. KeplAI uses vector embeddings (OpenAI’s embedding model + Qdrant vector store) to match extracted entities against existing ones. The user sees candidates ranked by similarity score and can confirm or reject. It’s not perfect -- “Apple” the company vs. “apple” the fruit still requires contextual reasoning that embeddings alone can’t fully capture -- but it handles the 80% case that used to require manual reconciliation.
Querying the Graph
SPARQL is a powerful query language. I write it fluently after years of practice. But I also know that asking a domain expert to write this is unreasonable:
PREFIX entity: <http://keplai.io/entity/>
PREFIX ontology: <http://keplai.io/ontology/>
SELECT ?company WHERE {
GRAPH ?g {
entity:Mehdi ontology:founded ?company .
?company ontology:industry "AI" .
}
}They want to ask: “What AI companies did Mehdi found?”
Translating natural language to SPARQL is where I’ve spent the most engineering effort in KeplAI, because this is where naive LLM usage falls apart spectacularly.
The core problem: LLMs invent predicates. Ask GPT-4 to generate SPARQL for “when was Tom Hanks born?” and it’ll confidently produce ontology:birthDate -- even when your graph uses ontology:bornOn. The LLM’s world knowledge overrides the schema context you provided. It’s the same hallucination problem, just manifesting in a structured output.
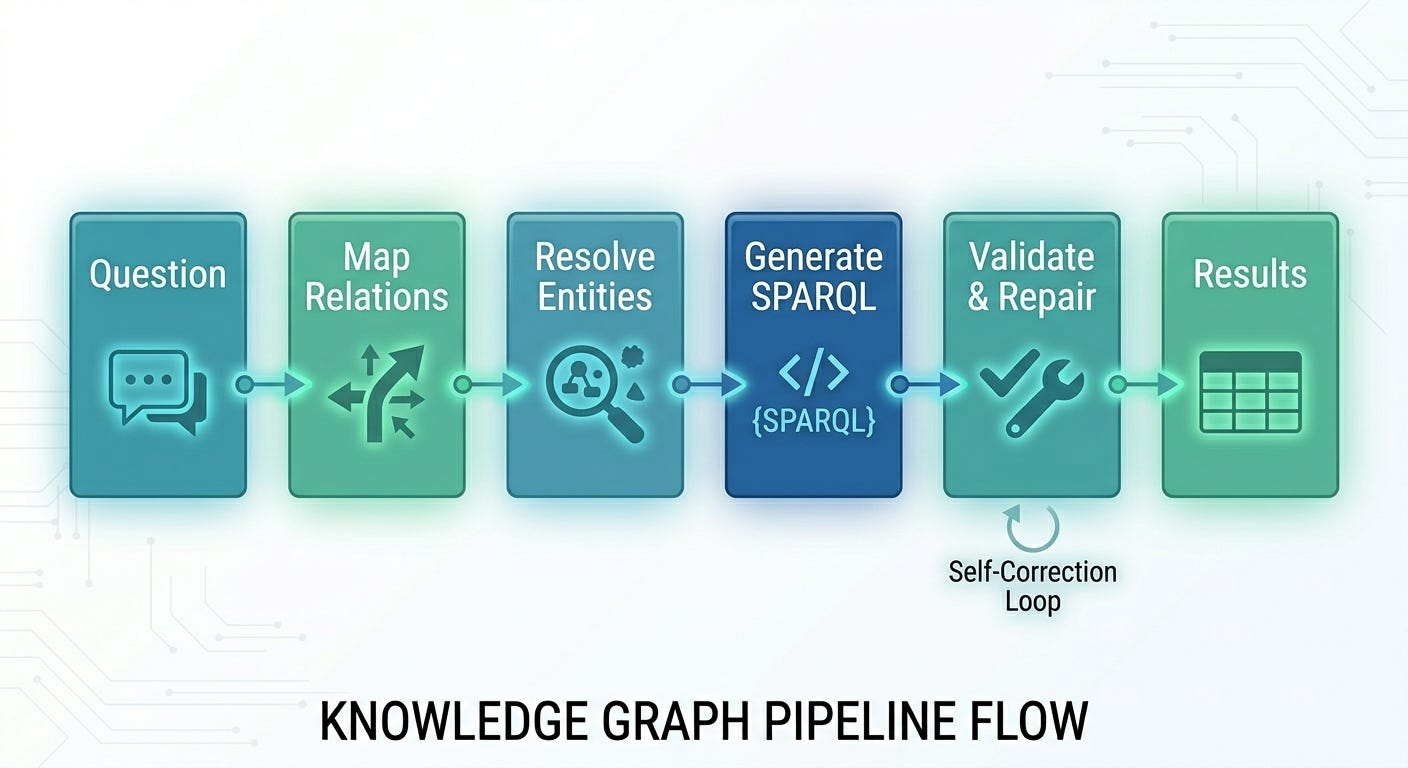
KeplAI’s NLQ engine addresses this with a multi-stage pipeline:
Relation mapping -- Before generating SPARQL, an LLM call maps natural-language phrases (”works at,” “born in”) to actual predicates in your graph. This produces explicit mappings that get injected into the generation prompt.
Entity resolution -- Entity mentions are extracted from the question and resolved against the graph via vector similarity. “Tom Hanks” becomes
entity:ThomasJeffreyHanks(or whatever your graph uses).Schema-grounded generation -- The SPARQL generation prompt includes the full property list (with descriptions), the entity mappings, the relation mappings, and explicit instructions to use only listed predicates.
Predicate validation -- After generation, every URI in the output SPARQL is checked against the allowed set. If the LLM invented
ontology:birthDatewhen onlyontology:bornOnexists, it’s flagged.Self-repair -- Invalid predicates trigger a repair call: “Your query uses these invalid predicates. Here are the allowed ones. Fix it.” This catches the 10-15% of queries where the LLM ignores the schema despite explicit instructions.
Is it perfect? No. Complex multi-hop queries still trip up sometimes. But for the vast majority of questions a domain expert would ask, it produces correct SPARQL -- and it shows the generated query alongside the results, so power users can verify and edit.
Use Cases Where This Actually Matters
Research Knowledge Management
This is closest to my own experience. A researcher imports domain ontologies (biomedical, legal, environmental), then feeds papers and documents through the extraction pipeline. The knowledge graph grows semi-automatically. They can ask “Which genes are associated with both diabetes and cardiovascular disease?” and get answers grounded in extracted data, with provenance tracking showing which paper each fact came from.
Enterprise Knowledge Unification
Organizations have knowledge trapped in wikis, Confluence pages, Slack threads, and people’s heads. A knowledge graph can unify this. Extract triples from documentation, connect them with organizational ontologies, and you have a queryable map of institutional knowledge. When someone leaves the company, their knowledge doesn’t leave with them.
Compliance and Auditing
Every triple in KeplAI can carry provenance: source document, extraction timestamp, method (manual vs. AI-extracted). In regulated industries -- healthcare, finance, legal -- being able to trace every fact back to its source isn’t a nice-to-have. It’s a requirement.
AI-Powered Applications
This is where I think the biggest opportunity lies. RAG (Retrieval-Augmented Generation) typically uses vector search over chunks of text. But knowledge graphs offer something vector search can’t: structured reasoning. Instead of retrieving “similar text,” you retrieve facts and their logical connections. An LLM grounded in a knowledge graph doesn’t just find relevant passages -- it follows relationship chains and provides answers with explicit provenance.
Hard-Won Technical Insights
A few things I want to share from building this that aren’t obvious from the outside:
Named graphs are essential but the ecosystem barely supports them. Almost every SPARQL tutorial teaches you to query the default graph. In practice, if you’re managing multiple ontologies with data isolation, everything lives in named graphs. This means every query needs a GRAPH ?g { ... } wrapper. Forget it, and you get zero results with zero helpful error messages. KeplAI auto-injects GRAPH clauses when the LLM forgets them -- a safety net born from painful debugging sessions.
The LLM-to-SPARQL “last mile” is harder than NL-to-SQL. SQL has a relatively flat structure -- tables, columns, JOINs. SPARQL has PREFIX declarations, URI resolution, named graphs, blank nodes, OPTIONAL patterns, FILTER expressions, and the RDF data model underneath. The LLM needs to get all of this right simultaneously. The relation mapping and predicate validation layers exist because a single wrong URI means the query silently returns nothing.
Ontologies compound in value over time. This is something you only appreciate after maintaining a knowledge graph for months or years. Early on, defining an ontology feels like overhead. Six months in, when auto-typing has correctly classified thousands of entities and inference has surfaced relationships you never explicitly stated, the upfront investment pays for itself many times over.
Entity disambiguation remains the hardest unsolved problem. After years of working on this, I’m convinced that pure vector similarity gets you ~80% of the way. The remaining 20% -- contextual ambiguity, cross-language entities, temporal references -- requires hybrid approaches combining embeddings with graph structure and contextual reasoning. This is active work.
The Architecture
For those who want to look under the hood:
KeplAI is SDK-first. The Python SDK (keplai) is the core -- it manages the graph, ontologies, and AI features and can be used standalone. The REST API (FastAPI) and Web UI (React + TypeScript) are layers on top.
The stack:
Apache Jena Fuseki -- standards-compliant RDF triplestore with SPARQL endpoint and OWL reasoning. The SDK manages Fuseki’s Docker lifecycle automatically.
OpenAI GPT-4 -- powers extraction, NL-to-SPARQL generation, and result explanation.
Qdrant -- vector similarity search for entity disambiguation.
OWL/RDFS reasoning -- built into the triplestore, so inference happens at the data layer, not the application layer.
The web UI provides a dashboard, triple management with batch operations, an ontology editor with multi-ontology support, a text extraction interface, a natural language query page, and an interactive force-directed graph explorer.
Open source under Apache 2.0: github.com/mallahyari/keplai.
The Bigger Picture
I’ve been in the semantic web world long enough to have seen multiple hype cycles come and go. Linked Data. The original Semantic Web vision. Knowledge graphs in enterprise. Each wave brought real progress but never achieved mainstream adoption.
This time feels different, and the reason is LLMs.
The fundamental thesis: LLMs are great at understanding language but hallucinate facts. Knowledge graphs are great at storing facts but are hard to query naturally. They’re complementary in a way that’s almost too clean.
LLMs as the interface to structured knowledge -- with the knowledge graph providing ground truth, provenance, and reasoning, and the LLM providing the natural-language bridge -- is, I believe, how the next generation of knowledge-intensive AI applications will be built. Not chatbots that make things up, but systems that reason over verified facts and can show their work.
KeplAI is my attempt to make that vision practical today. It’s not finished -- the NLQ pipeline needs more work on complex queries, the disambiguation could be smarter, and there are a dozen features on the roadmap. But it’s usable now, and the best way to improve it is for people to use it and push against the edges.
If you’ve been curious about knowledge graphs but put off by the tooling, or if you’re a semantic web veteran wondering how LLMs fit into the picture, give it a try.

KeplAI is open source and available at github.com/mallahyari/keplai.
"Entity disambiguation remains the hardest unsolved problem"
This is "clearly" what is missing in the semantic web arena... paradoxically