
How to Choose Base Model for Your LLM Application 🧐?

The field of Large Language Models (LLMs) is flourishing with numerous models, continuously evolving day-by-day. If you want to develop an LLM application for production, which model on the market should you choose?
Should we prioritize the best-performing model on the market? GPT-4 undoubtedly stands out as a top contender.
Should we consider privacy-aware LLMs due to the paramount concerns surrounding data privacy these days? An viable option can be the GPT4ALL as we introduced earlier.
Or should we consider an open-source that is fine-tunable like Google’s T5?

Dimensions of consideration
To summarize, your checklist should encompass careful consideration of the tradeoffs among the following essential dimensions:
“Out-of-the-box quality for your specific task.
Inference speed and latency to ensure optimal performance.
Cost implications that align with your budget and resources.
Fine-tuneability and extensibility for a customized fit to your requirements.
Data security and privacy measures to safeguard sensitive information.
License permissibility, ensuring compliance with licensing terms and restrictions.”
Proprietary or open-source?
The short answer is that the proprietary models are generally better. Proprietary models tend to offer superior performance and overall quality. They often outshine their open-source counterparts, which can be hindered by licensing complexities, making them less favorable for commercial use. Moreover, serving open-source models can introduce infrastructure overhead.
It’s much easier to just call an API.
Of course, there are use cases that you would really need open source. For instance, they are much easier to customize; or if you are looking for something that excels in data security.
Licensing friction
If you opt for open-source models, it's crucial to pay close attention to licensing considerations. Here are the key differences to consider:
“Permissive licenses: e.g. Apache 2.0 let you do more-or-less what you want with the model.
Restricted licenses: e.g. CC BY-SA 3.0 place restrictions on commercial use, but don’t prohibit it. You’ll need to draw your own conclusions on whether this works for your use case.
Non-commercial licenses: e.g Meta proprietary ones or Creative Commons CC BY-NC-SA 4.0 explicitly prohibit commercial use and are a bad choice for building apps”
Proprietary contenders
One page to illustrate some example contenders:
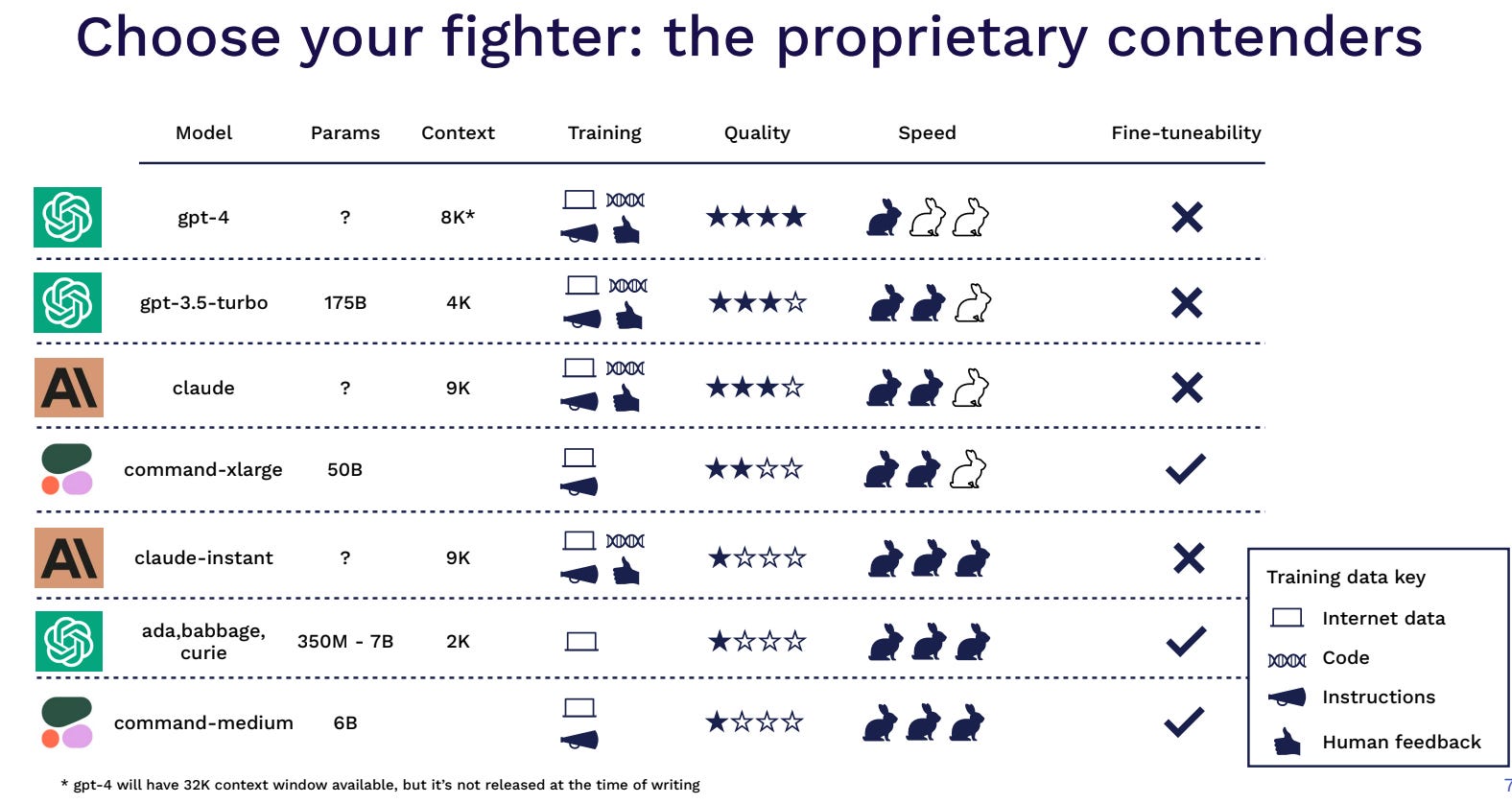
The above table assesses some of the critical factors for choosing a model such as context window (maximum number of tokens that the model can take as input during inference) - short context window can lead to incomplete understanding and choppy responses in a conversational AI application. The parameters and training data are proxies for the quality of the model - generally the more the better. Notably, GPT4 and GPT3.5 models stand out, having undergone extensive training beyond just the internet data, incorporating code data to enhance their performance.
GPT4 reigns as the market's pinnacle LLM in terms of quality, while GPT3.5 offers a faster and more cost-effective alternative with minor performance tradeoffs. For exceptional OpenAI alternatives, Claude by Anthropic emerges as a compelling choice. Cohere’s Command-XL stands out as a high-quality and fine-tunable option, providing quality and customization. The three options at the bottom of the list are better in pricing and speed.
Open-source contenders
Again, one page to illustrate some examples:

License is important in this case. The green ones represent the most permissive licenses, offering greater freedom, while the red ones are best suited for experimentation rather than practical use. Among these, T5 stands out as a promising option, combining decent quality with a permissive license.
Llama and the latest Llama 2 share the same license. Although Meta claims they are free for commercial use, certain restrictions do exist.
The options towards the bottom of the list (and similar ones) do not worth consideration due to lack of quality.
Recommendations
For a robust proof of concept and to align with your use case, it’s recommended starting with GPT-4/3.5. Focus on exploring its potential for your product-market fit. In most cases, if GPT-4/3.5 cannot address your specific use case, it's unlikely that other weaker models will suffice.
Once your app clears the feasibility test, and if cost or latency is critical, then you can consider downgrade. From GPT4 to GPT3.5 or Claude can be viable options and they are pretty comparable in performance. For optimal fine-tuning capabilities, Cohere stands out as a top choice.
In essence, begin with GPT-4 (or 3.5) and only turn to open-source alternatives if restrictions arise.
Looking forward to seeing what y’all are building!

Happy creating!
Thanks for reading my newsletter. You can follow me on Linkedin or Twitter @Angelina_Magr!
Keep reading with a 7-day free trial
Subscribe to The MLnotes Newsletter to keep reading this post and get 7 days of free access to the full post archives.