
How to Build a Research AI Agent with Vanilla Python in Less Than 2 Hours


What if I told you that you could build one yourself using vanilla Python in less than two hours?
In this blog post, we'll explore how to create a powerful research AI agent using minimal dependencies and flexible tools. Let's dive in!
Why Build a Custom Research Assistant?
Research and summarization are among the most common use cases for AI agents in industry. While there are existing solutions like LangChain's tutorial for building a fully local research assistant, we're going to take a different approach. Our goal is to recreate similar functionality while minimizing dependencies and using vanilla Python as much as possible.
The Benefits of Minimizing Dependencies
By reducing the number of third-party libraries and tools, we make our research assistant:
Less vulnerable to changes in external packages
Easier to maintain in the long term
More flexible and customizable to our specific needs
Core Components of Our Research AI Agent
Our research assistant will consist of several key components:
Search query generation
Web search functionality
Content summarization
Reflection and knowledge gap identification
We'll implement these components using the Pydantic AI framework and Light LLM for maximum flexibility.
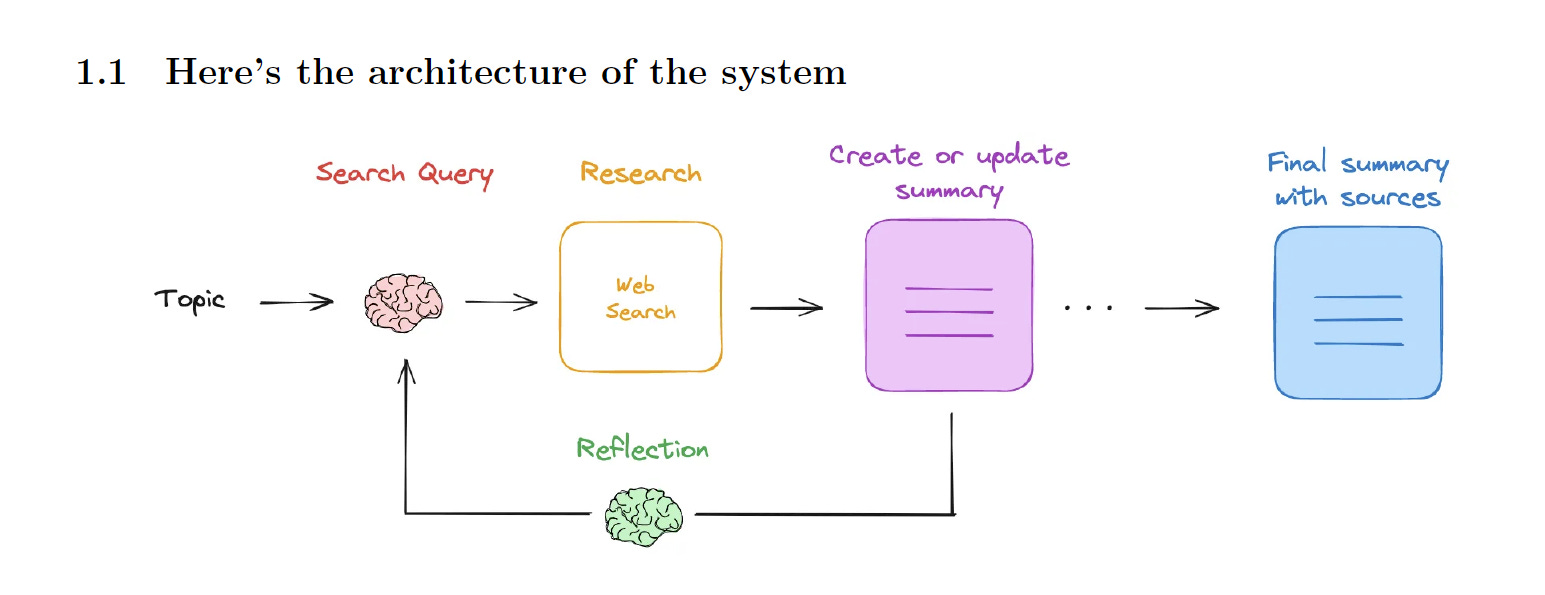
The Research Assistant Workflow
Here's a high-level overview of how our research assistant will work:
Accept a research topic from the user
Generate a search query based on the topic
Perform a web search and collect relevant links and content
Summarize the collected information
Reflect on the summary to identify knowledge gaps
Repeat steps 2-5 for a configurable number of iterations
Generate a final summary with sources
Implementing the Core Functions
Let's break down the main functions we'll need to implement:
1. Generate Search Query
def generate_search_query(context):
# Use LLM to generate a targeted search query
# based on the research topic and current summary
pass
2. Perform Web Search
def perform_web_search(context):
# Use a search API (e.g., Tavily) to fetch search results
# Format and store the results
pass
3. Summarize Sources
def summarize_sources(context):
# Summarize the content from all collected sources
# Incorporate existing summary if available
pass
4. Reflect on Summary
def reflect_on_summary(context):
# Analyze the current summary and original topic
# Identify knowledge gaps for further research
pass
Curious to learn more?
Join Professor Mehdi and myself for a discussion about this topic below:
What you’ll learn 🤓:
🔎 Comparison to LangGraph implementation
🚀 Core architecture components: search query generation, web search, summarization, reflection
🦄Step-by-step code walk through
🪄 How to make it fully local by changing LLM
👇
Before we go on…a quick announcement -
🚀 Join Our New YouTube Membership Community!
For many of you following us on YouTube. thank you so much for your support! 🦄
In addition to our regular updates, I’m excited to announce the launch of our membership community! Whether you’re looking to master Retrieval-Augmented Generation (RAG), AI Agents, or dive deep into advanced AI projects and tutorials through AI Unbound, there’s something for everyone passionate about AI.
By joining, you’ll gain exclusive content, stay ahead of the curve, and reduce AI FOMO while building real-world skills. Ready to take your AI journey to the next level?
Let’s build, learn, and innovate together!
Leveraging Pydantic AI Dependencies
One powerful feature of Pydantic AI is the ability to create dependencies that can be accessed across different tools. We'll define a
class ResearchDependencies:
research_topic: str
search_query: str
current_summary: str
final_summary: str
sources: List[str]
latest_web_search_result: str
research_loop_count: int
By using these dependencies, we can easily share information between our tools and maintain the state of our research process.
Creating a More Autonomous Agent
Unlike some implementations that define a strict workflow, our approach gives the agent more autonomy. We provide a general system prompt and a set of tools, allowing the agent to decide which steps to take based on the task at hand.
agent = Agent(
llm=llm,
system_prompt="You are a researcher. Use your tools to provide research...",
tools=[generate_search_query, perform_web_search, summarize_sources, reflect_on_summary],
dependencies=ResearchDependencies()
)
This approach makes our agent more flexible and capable of adapting to different research scenarios.
Flexibility in LLM Choice
One of the great advantages of our implementation is the ease with which we can switch between different language models. By using Light LLM, we can change our model with a single line of code:
llm = completion(model="gpt-4",...) # Can be easily changed to other models
This flexibility allows us to use various LLMs, including open-source models run locally, making it simple to create a fully local research assistant if desired.
Sample Output and Execution
When we run our research assistant, we'll see output similar to this:
Generating search query...
Performing web search...
Summarizing sources...
Reflecting on summary...
[Repeat for configured number of iterations]
Final summary:
[Research summary with sources]
This output demonstrates the agent's autonomous decision-making as it progresses through the research process.
Potential Improvements
While our current implementation is powerful, there's always room for enhancement. Some potential improvements include:
Removing duplicate search results across multiple queries
Generating and searching for multiple sub-topics in parallel
Implementing more advanced filtering and relevance scoring for search results
Adding support for different types of content (e.g., academic papers, news articles)
Conclusion
Building a research AI agent with vanilla Python in less than two hours is not only possible but also highly rewarding. By leveraging flexible frameworks like Pydantic AI and Light LLM, we can create a powerful, customizable, and maintainable research assistant that adapts to our specific needs.
Minimizing dependencies leads to more robust and maintainable code
Using flexible tools allows for easy customization and expansion
Giving the agent more autonomy can result in more adaptable research processes
The ability to easily switch between different LLMs provides great versatility
With this foundation, you can now build and customize your own research AI agent to supercharge your information gathering and analysis processes. Happy researching!
🛠️✨ Happy practicing and happy building! 🚀🌟
Thanks for reading our newsletter. You can follow us here: Angelina Linkedin or Twitter and Mehdi Linkedin or Twitter.
🌈 Our RAG course: https://maven.com/angelina-yang/mastering-rag-systems-a-hands-on-guide-to-production-ready-ai
📚 Also if you'd like to learn more about RAG systems, check out our book on the RAG system: You can download for free on the course site:
https://maven.com/angelina-yang/mastering-rag-systems-a-hands-on-guide-to-production-ready-ai
🦄 Any specific contents you wish to learn from us? Sign up here: https://noteforms.com/forms/twosetai-youtube-content-sqezrz
🧰 Our video editing tool is this one!: https://get.descript.com/nf5cum9nj1m8
📽️ Our RAG videos: https://www.youtube.com/@TwoSetAI
📬 Don't miss out on the latest updates - Subscribe to our newsletter:

That is golden! thank you so much