
Data Science Interview Challenge

Welcome to today's data science interview challenge! Today’s challenge is inspired by a talk by Professor Trevor Hastie from Stanford at the University of Bristol. Here it goes:
Question 1: Let’s say you work for a digital marketing company. You are given a dataset for five-minute internet sessions totaling 64MM rows of data. There are 7 million features of session info (such as web page indicators, descriptors and so on).
Our goal is to predict if any five-minute session is watched by family with children or no children. With this, the advertisers can take caution of displaying specific ads.
How would you go about to build a model to solve this?
Question 2: Can you explain the following graph from the training result? Are we overfitting here?
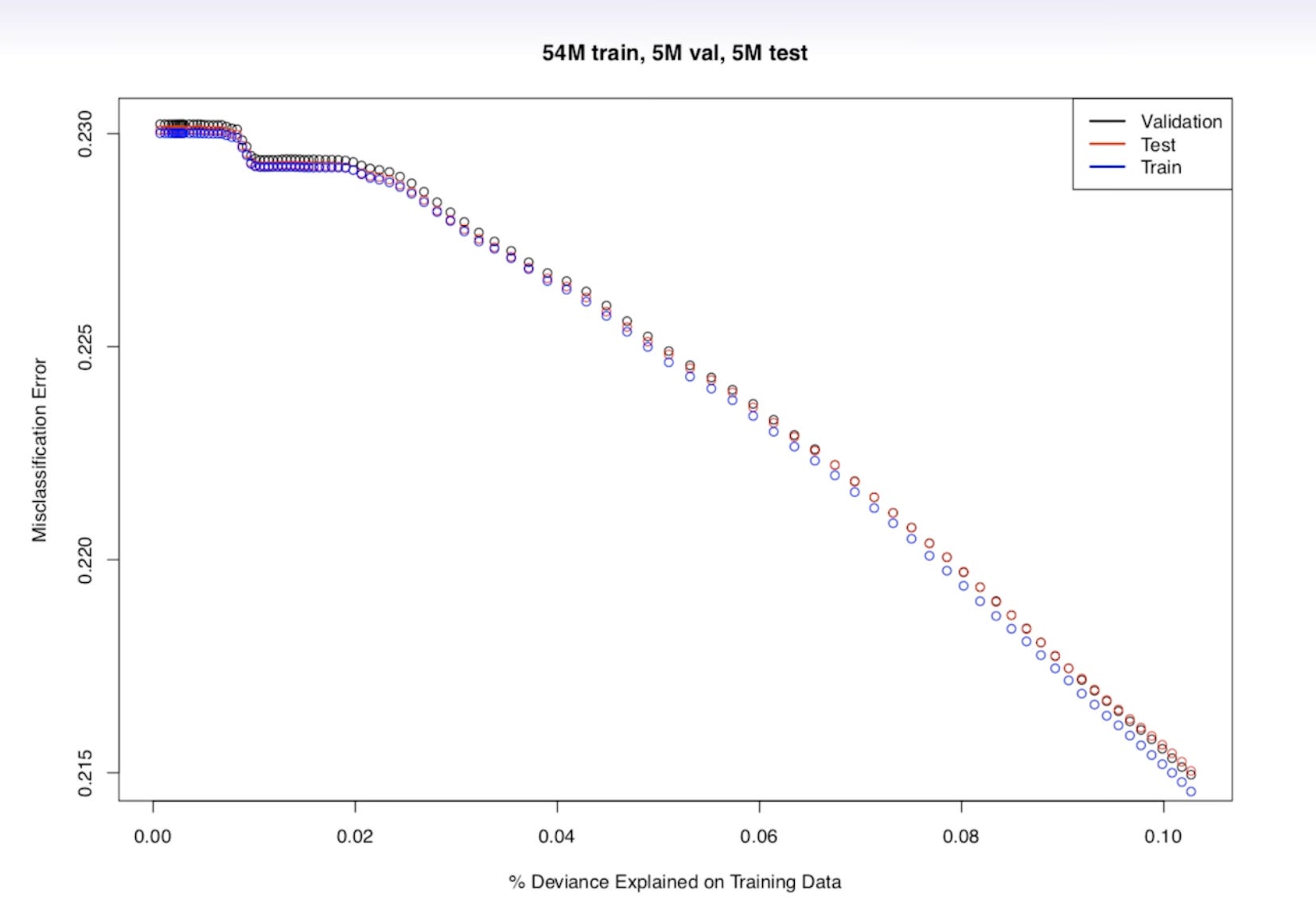
Here are some tips for readers' reference:
Question 1:
There are many ways you can solve this problem. For instance, we can use a binary classification model that has the target looks like the following:
FamilyWithChildren = 1: This indicates that the five-minute internet session was watched by a family with children.
FamilyWithChildren = 0: This indicates that the five-minute internet session was not watched by a family with children.
We have 7 million features. We can choose to reduce dimension by using Principal Component (PCA), or simply remove sparse features. In this case, Trevor removed all features with less than 3 non-zero values, which reduced the number of features to one million.
Then split the model into training, test and validation sets for model development. A model that can be used here may be glmnet if you are using R, or scikit-learn, statsmodels for python.
Question 2:
Check how Professor Trevor Hastie explains this:
Keep reading with a 7-day free trial
Subscribe to The MLnotes Newsletter to keep reading this post and get 7 days of free access to the full post archives.