Agentic RAG: Make Retrieval a Decision, Not a Step

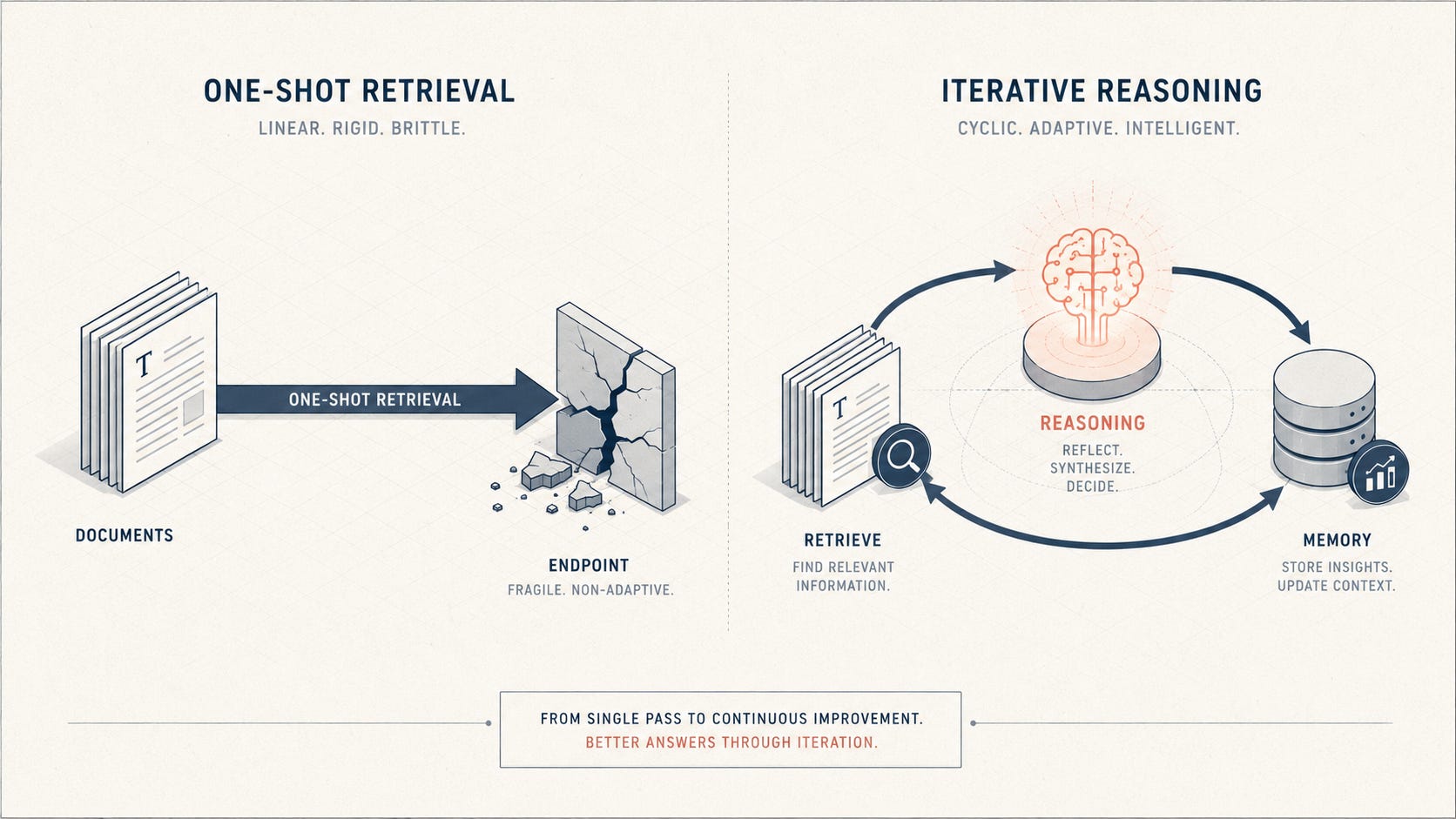
Here’s the uncomfortable truth almost every RAG tutorial skips: the standard RAG pipeline doesn’t actually work beyond the demo.
You know the recipe, embed your documents, retrieve the top-k chunks for a query, stuff them into a prompt, hope for the best. It looks magical on a curated example. Then you put it in front of real users and it falls apart: someone asks a two-part question and the single retrieval grabs context for half of it and makes up the rest. Someone uses an exact term your embedding model doesn’t understand and gets nothing. Someone asks something the docs don’t cover and the model confidently invents an answer with a citation that doesn’t exist.
These aren’t bugs you can tune away. They’re structural. Naive RAG retrieves once, blindly, before the model has thought about anything, and then it’s stuck with whatever it got. The system never gets to decide it should search again, search differently, read more, or admit it doesn’t know.
The fix isn’t a better embedding model or a bigger context window. It’s a different architecture: agentic RAG, where retrieval itself becomes agentic. The model decides when to search, rewrites its own queries, runs as many retrieval rounds as the question needs, pulls more context only where it’s thin, and, the part I care about most, refuses to cite a source it didn’t actually retrieve.
This post builds one end to end so you can see exactly why the agentic version wins. The project runs on LiteLLM (multi-provider, searching for a replacement though ;) ), LanceDB (vectors), full text search (BM25), and a local embedding + reranking stack. Let’s build it up piece by piece.
The shape of the thing
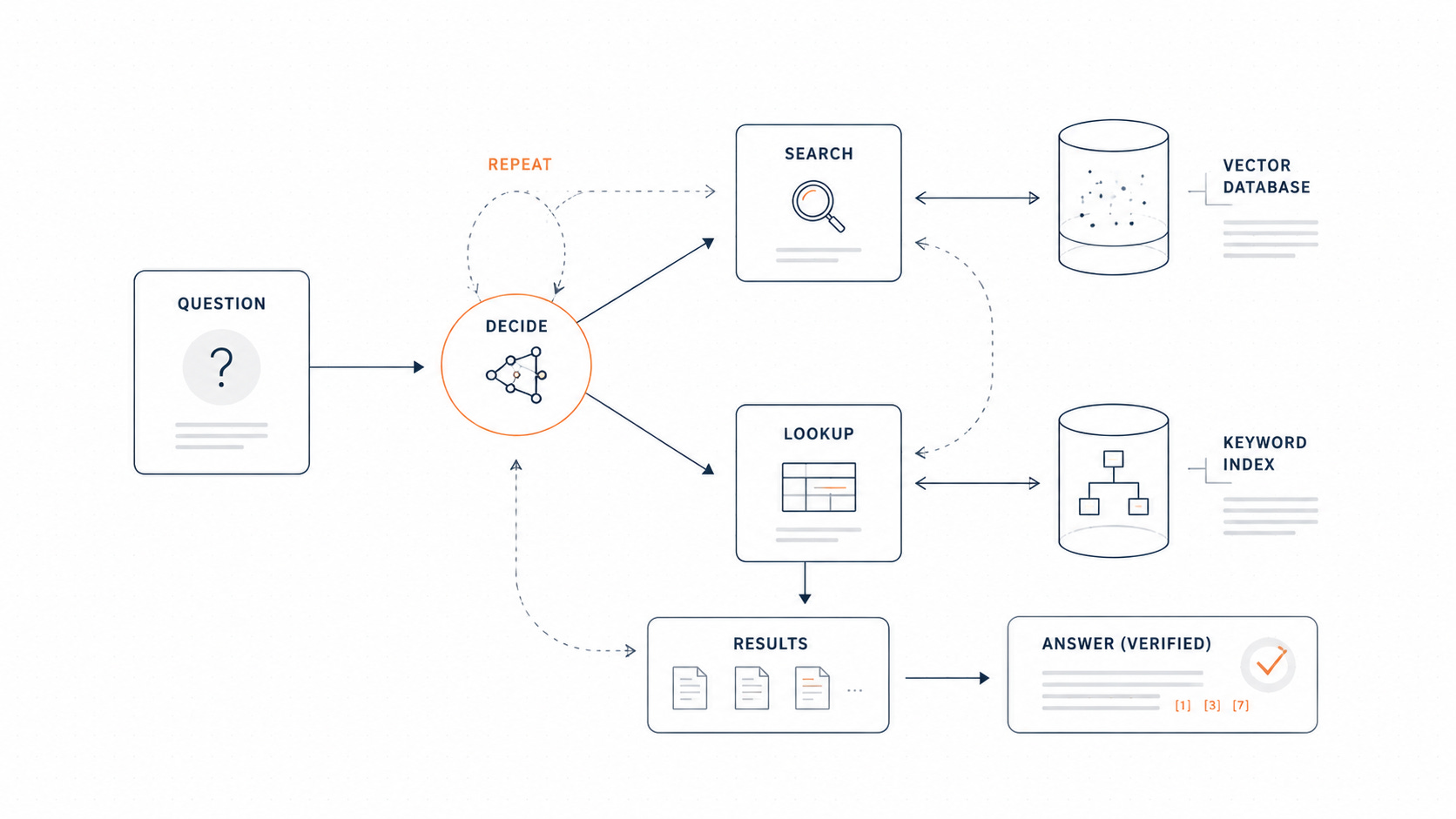
Before any code, here’s the mental model. There are two pipelines: an offline one that gets documents into searchable shape, and an online one that answers questions.
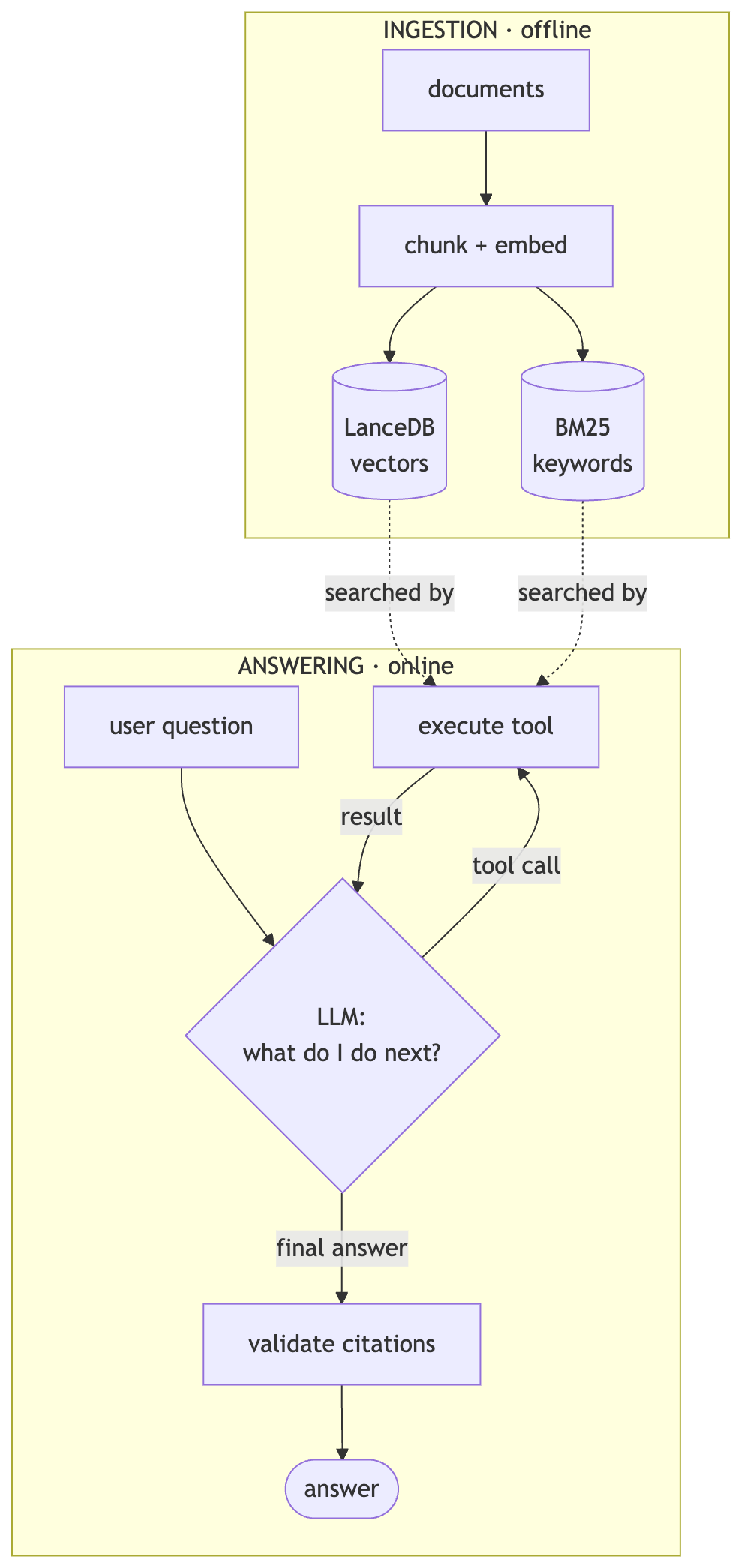
The dashed lines show where the two halves meet: the indexes built offline are what the agent’s execute tool step searches at question time. And the loop label matters, the model can cycle LLM → tool → result → LLM up to 10 times before it commits to an answer.
The key difference lives in that loop on the right. Naive RAG is a straight line: retrieve → generate, once, and you live with it. Agentic RAG is a cycle the model drives, and that single architectural change is what turns retrieval from a blind guess into a deliberate search.
Part 1, Ingestion: getting documents in
Nothing exotic here, but two decisions matter.
Chunk with overlap, and give every chunk a positional ID. I split text into 512-character chunks with 64 characters of overlap, and ID them sequentially:
def _chunk_id(doc_id: str, index: int) -> str:
return f"{doc_id}__c{index:04d}" # paper__c0000, paper__c0001, ...That c0000, c0001 ordering isn’t cosmetic, it’s what lets the agent later say “give me the chunks around this one” to read more of a document. The ID encodes position.
Embed locally, and build two indexes. Each chunk is embedded with BAAI/bge-small-en-v1.5 (a small, fast, 384-dim model that runs on your machine, no embedding API bill), stored in LanceDB, and also indexed by BM25:
vectors = embed(texts, "BAAI/bge-small-en-v1.5") # normalized, local
insert_chunks(db, chunks) # → LanceDB (semantic)
rebuild_index(collection, all_ids, all_texts) # → BM25 (keyword)Why two indexes? Because semantic search and keyword search fail in opposite ways, and we’re about to use that. Notice: LanceDB also has full text search, but I decided to implement it separately.
Part 2, Retrieval that doesn’t suck: hybrid search

Pure vector search is great at meaning (”car” matches “automobile”) and terrible at specifics, exact names, error codes, acronyms like “GNN-RAG” that don’t sit near anything in embedding space. Keyword search (BM25) is the mirror image: nails the exact term, misses the paraphrase.
The fix is to run both and merge the rankings. The merge trick is Reciprocal Rank Fusion (RRF), and it’s beautifully simple. You don’t try to reconcile the two scoring systems (cosine similarity vs. BM25 scores aren’t comparable). You throw the scores away and only use rank position:
def _rrf(semantic, keyword, k: int = 60):
"""Reciprocal Rank Fusion over two ranked lists, keyed by chunk_id."""
scores = {}
for rank, r in enumerate(semantic):
scores[r.chunk_id] = scores.get(r.chunk_id, 0.0) + 1.0 / (k + rank + 1)
for rank, r in enumerate(keyword):
scores[r.chunk_id] = scores.get(r.chunk_id, 0.0) + 1.0 / (k + rank + 1)
return scoresA chunk that ranks #1 in both lists rises to the top. A chunk that’s #1 in one and absent from the other still scores respectably. The k=60 constant dampens the contribution of low-ranked items, it’s the standard value from the original paper and you rarely need to touch it.
Then one more pass: a cross-encoder reranker (ms-marco-MiniLM). The bi-encoder embeddings we used for retrieval encode the query and document separately, fast, but it can’t model how they relate. A cross-encoder reads the query and a candidate chunk together and scores the pair directly. It’s too slow to run over the whole corpus, but perfect for re-ranking the ~10 candidates RRF handed us down to the best 5.
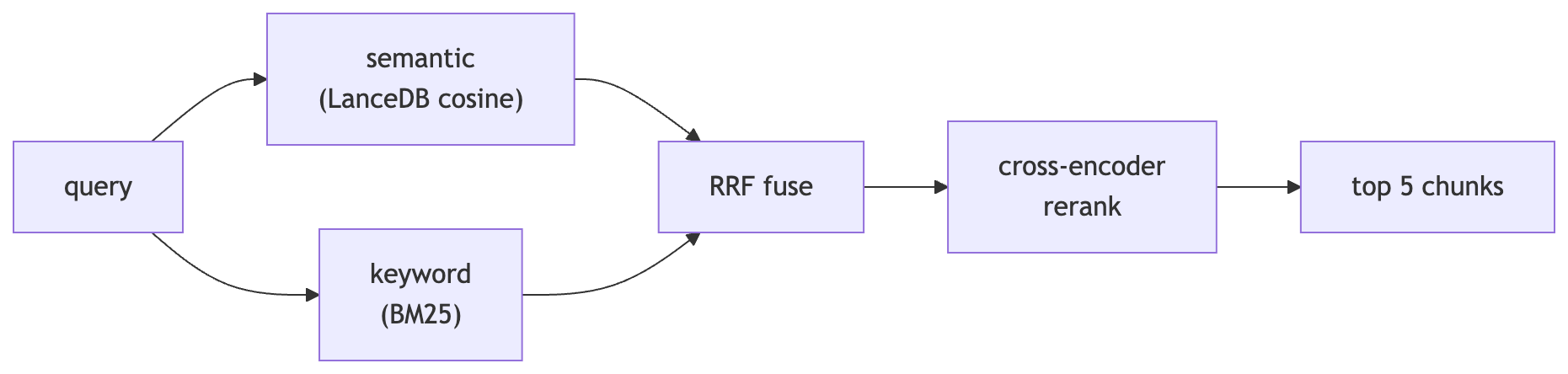
This whole stack, embed, search, fuse, rerank, is one tool call from the agent’s point of view. Which brings us to the interesting part.
Part 3, The agent loop
Here’s the heart of the system. Instead of retrieving once, the agent runs a ReAct loop: reason, act, observe, repeat. Stripped down, it’s this:
for iteration in range(MAX_ITERATIONS): # cap at 10
stream = await stream_completion(messages, tools, ...)
# ... collect the model's response: either text or tool calls ...
if finish_reason == "stop": # model wrote an answer
correction = validate_citation(answer, retrieved_ids)
if correction: # caught a bad citation
messages.append(correction) # tell it to fix, loop again
continue
return answer # clean — we're done
if tool_calls: # model wants to use a tool
for call in tool_calls:
result = dispatch_tool(call.name, call.args)
messages.append(result) That’s the entire control flow. Every iteration, the model looks at the conversation so far, including the results of any searches it already ran, and decides the next move. Search again with a better query? Pull more context around a promising hit? Or does it finally have enough to answer?
This is what “agentic” actually means in practice. Not a personality, not magic, just a loop where the model chooses the next action and sees the consequences before choosing again. Retrieval stops being a preprocessing step and becomes a decision the model makes, repeatedly, with feedback. That’s agentic retrieval, and it’s the whole ballgame.
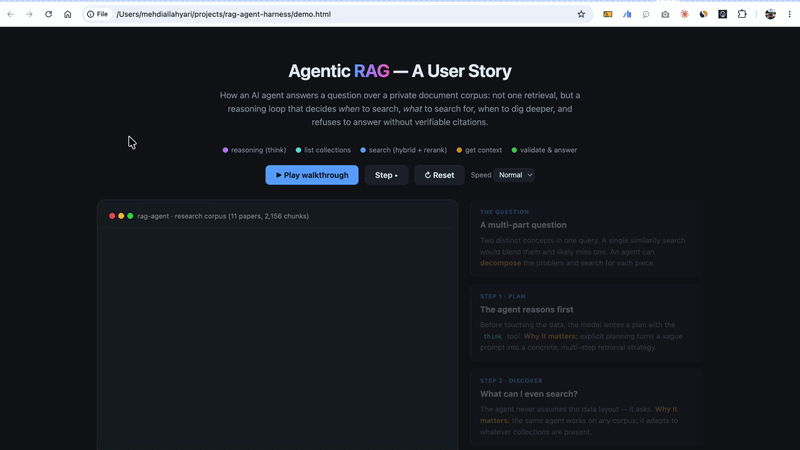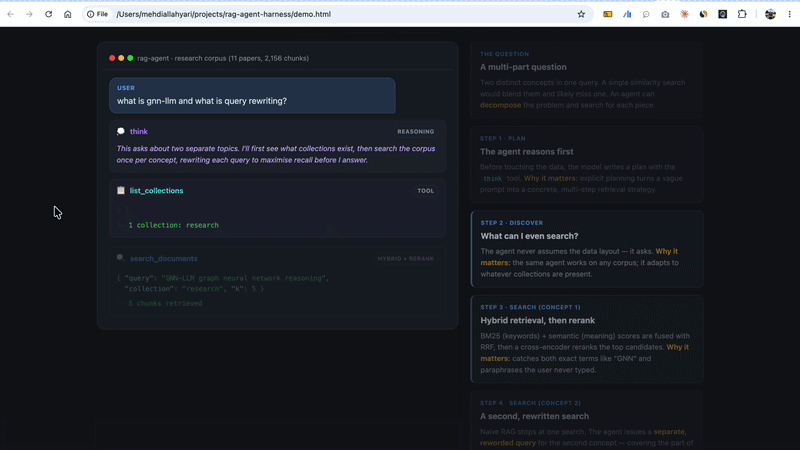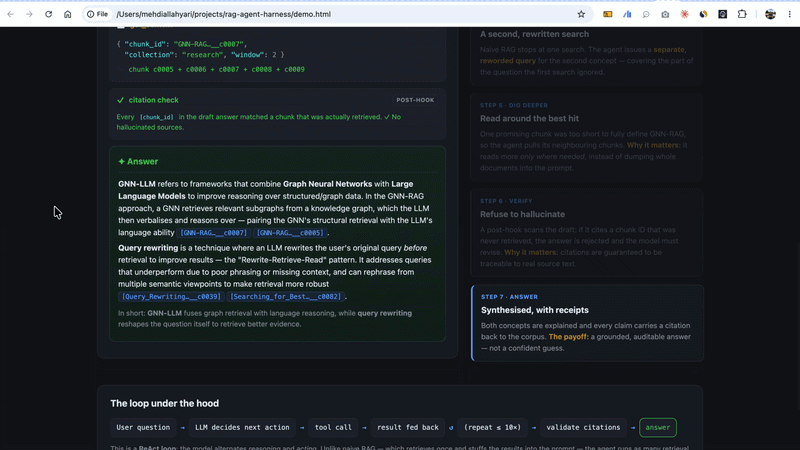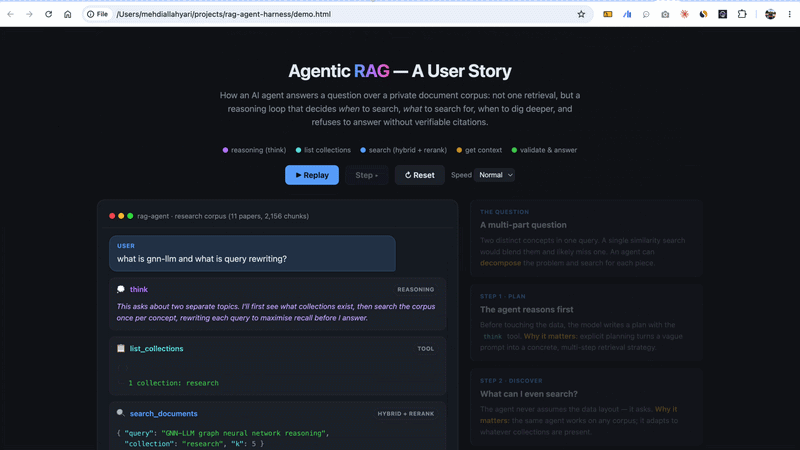
A real trace for “What is GNN-LLM and what is query rewriting?” looks like:
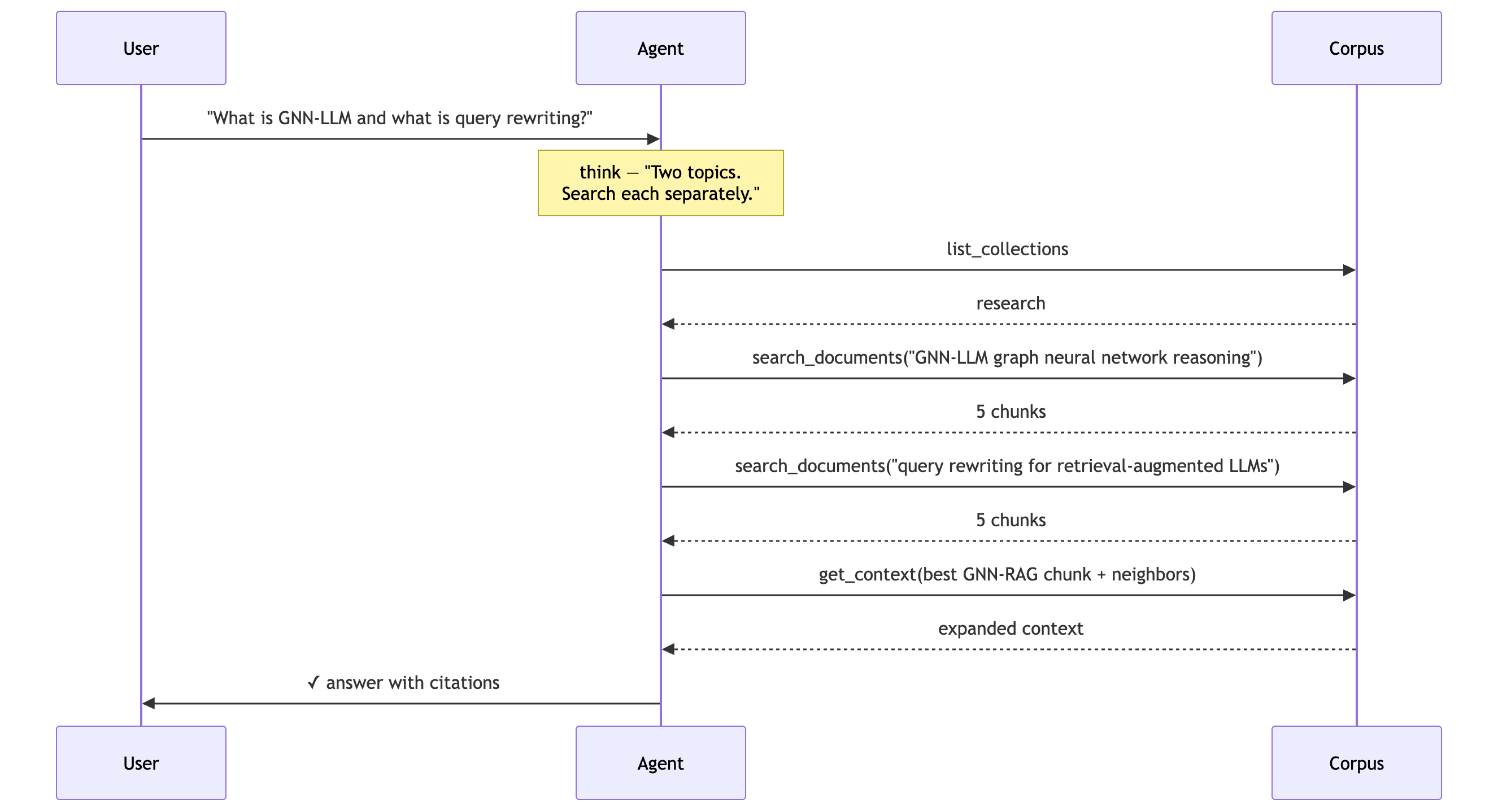
Two searches, not one, because it’s a two-part question. Then a third call to read around the best hit, because one chunk wasn’t enough. A naive pipeline physically cannot do any of this. It gets one shot at one query and is done. This is the exact failure I opened with, and here’s the architecture that removes it.
Part 4, The tools: the agent’s hands
The agent can only do what its tools let it. I gave it four, deliberately small:

get_context is the quiet hero. When a search hit is relevant but too short to fully answer from, the agent fetches the surrounding chunks (using those positional IDs from Part 1) instead of dumping the entire 40-page document into the prompt. It reads deeply, but only where it’s worth it, which keeps the context window (and your token bill) under control.
There’s a hard budget enforced around every retrieval, too: once retrieved content crosses ~8,000 tokens, further searches are blocked and the model is told to answer with what it has. Agents left unsupervised will happily search forever.
Part 5, The part that builds trust: citation validation
This is the feature I’d fight to keep. An agent that retrieves well is useful. An agent that can’t lie about its sources is something you can put in front of users.
After the model writes an answer, a post-hook checks every [chunk_id] citation against the set of chunks actually retrieved during this session:
def validate_citation(answer, retrieved_ids):
cited = parse_cited_ids(answer) # IDs in [brackets]
unknown = cited - retrieved_ids # cited but never retrieved
if unknown:
return (f"Citation error: {unknown} were not in your retrieved results. "
f"Valid chunk IDs you can cite: {sorted(retrieved_ids)[:6]}. ")
return None If the model invents a citation, or cites something it merely “remembered” from training instead of retrieved, the answer is rejected. The correction goes back into the loop and the model has to revise, up to a few attempts before it gives up gracefully. The result: every bracketed citation in a final answer is guaranteed to point at real, retrieved source text. No silent hallucinated references.
(Getting this right took a few tries. My first version’s regex also matched footnote markers like [1] and [Smith 2023] inside the document text, poisoning the set of “valid” IDs and sending the agent into an apology spiral. Validation logic that runs on model output is worth testing carefully, the failure modes are subtle.)
Multi-provider, almost for free
One design choice paid off repeatedly: every LLM call goes through LiteLLM, so the provider is just a config string.
PROVIDERS = {
"gemini-fast": ProviderConfig(model="gemini/gemini-2.5-flash"), # default
"anthropic-smart": ProviderConfig(model="claude-sonnet-4-6", enable_thinking=True),
"openai-fast": ProviderConfig(model="gpt-4o-mini"),
# ...
}python main.py --provider anthropic-smart "What are the key risks?"Same agent loop, same tools, same validation, swap the brain underneath. This is also how you A/B a cheap-and-fast model against a smart-and-slow one on your actual workload, which is the only benchmark that matters. (Each provider has its quirks, Gemini, for instance, tacks hidden “thought signature” tokens onto tool-call IDs mid-stream, which you have to strip before the conversation history will round-trip. The abstraction smooths the API, not the behavior.)
Seeing it think
A loop you can’t observe is a loop you can’t debug or trust. The agent streams every step, tool calls, arguments, results, and the final answer, to whatever UI is attached: a Rich-powered terminal view, or a Chainlit browser UI that renders each tool call as an expandable step above the streamed answer.
It matters more than it sounds. Watching the agent decide to run a second search because the first didn’t cover the whole question is the moment “agentic RAG” stops being a buzzword and starts being an obviously-better design.
What I’d tell you before you build your own
A few takeaways from building this:
The loop is the whole idea. Everything else, hybrid search, reranking,
budgets, is quality tuning. The thing that makes retrieval agentic is ten
lines: decide, act, observe, repeat. That’s the line between “doesn’t work in
production” and “does.”
Hybrid search is non-negotiable for real documents. Vector-only retrieval
will embarrass you the first time someone searches for an exact term or an
acronym.
Validate the model’s output, not just its input. Citation checking turned a
“usually grounded” system into a “provably grounded” one, and it’s maybe 30 lines.
Make it observable from day one. Most of my hardest bugs were invisible until I could watch the steps stream by.
Keep the tools small and sharp. Four focused tools beat one giant
do-everything tool the model has to reason about.
Stop shipping naive RAG
If there’s one thing to take from this: the one-shot retrieve-then-generate pipeline is a dead end for anything real. It demos beautifully and fails quietly, wrong on multi-part questions, blind to exact terms, and happy to hallucinate a citation when the docs come up empty. You can’t tune your way out of a structural flaw.
Agentic RAG fixes it at the root by making retrieval a decision the model makes, not a step that happens to it. The model searches when it needs to, searches again when the first attempt falls short, reads deeper only where it pays off, and can’t claim a source it didn’t pull. None of it is exotic, it’s a loop, two indexes, and a validator. But that combination is the difference between a demo and a system you’d actually put in front of users.
If you’re still building one-shot RAG, you’re building the version that breaks. Build the agent instead.
Built with LiteLLM, LanceDB, BM25 + cross-encoder reranking, and a strict citation validator. The full project is on GitHub mallahyari/rag-agent-harness, and if you want the annotated, step-through version of the example trace above, there’s an interactive walkthrough in the project repo, interactive walkthrough.