

Unlocking the Power of LLM with GraphRAG🦄
Unlocking the Power of LLM with GraphRAG🦄

In today’s data-driven world, the ability to extract meaningful insights from vast troves of unstructured information has become increasingly crucial.
This is where Microsoft’s GraphRAG, a graph-based Retrieval-Augmented Generation (RAG) system, steps in to revolutionize the way we interact with and understand complex datasets.
GraphRAG is a powerful tool that leverages the capabilities of large language models (LLMs) to automatically derive a rich knowledge graph from any collection of text documents. This graph-based data index is a game-changer, as it allows for a more structured and comprehensive approach to information retrieval and response generation.
One of the most exciting features of GraphRAG is its ability to provide hierarchical summaries of the data, offering an overview of the dataset without the need to know specific questions in advance. By detecting “communities” of densely connected nodes in the knowledge graph, GraphRAG can partition the data into high-level themes and more granular topics, creating a multi-level understanding of the information.
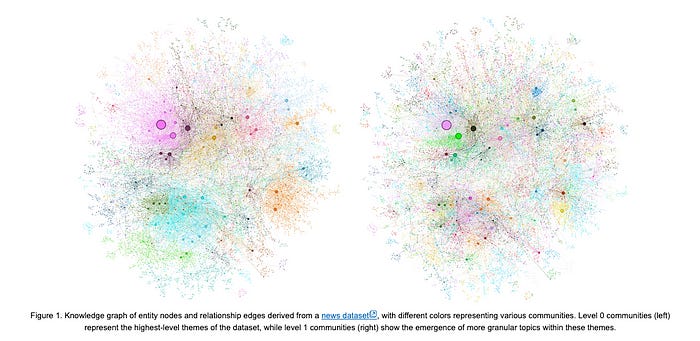
These community summaries are not just a visual aid; they also serve as the foundation for a new class of global queries that traditional RAG approaches struggle with. Imagine asking a question like “What are the main themes in the dataset?” This type of query, which addresses the entire dataset rather than focusing on specific chunks of text, is where naive RAG approaches often fall short.
The reason for this is that naive RAG generates answers based on the top-k most similar chunks of input text, which may not necessarily contain the information needed to answer a global question.
In contrast, GraphRAG’s community summaries have already considered all input texts in their construction, allowing for a more comprehensive and accurate response.
To evaluate the performance of GraphRAG, the research team used the LLM GPT-4 to generate a diverse set of activity-centered sense-making questions from short descriptions of two datasets: podcast transcripts and news articles.
The results were impressive, with GraphRAG outperforming naive RAG on comprehensiveness and diversity by a significant margin (70–80% win rate). GraphRAG also performed better than hierarchical source text summarization on these metrics, all while using substantially fewer tokens per query (2–3% for the highest-level communities).
These findings demonstrate the power of GraphRAG’s structured approach to data understanding and question answering. By leveraging the rich knowledge graph and hierarchical community summaries, GraphRAG is able to provide
Keep reading with a 7-day free trial
Subscribe to The MLnotes Newsletter to keep reading this post and get 7 days of free access to the full post archives.