

Meta's Llama 3 Summary


Today’s post is a recap of the popular Llama 3 model.
Enhanced Scalability and Performance
Meta Llama 3, the latest version of the LLM (Language Model) developed by Meta, introduces two new parameter models: the 8B and 70B parameter models [1]. These models represent a significant leap over the previous Llama 2 model and establish a new state-of-the-art for LLM models at these scales [1]. With increased parameters, Llama 3 is capable of handling more complex and diverse tasks.
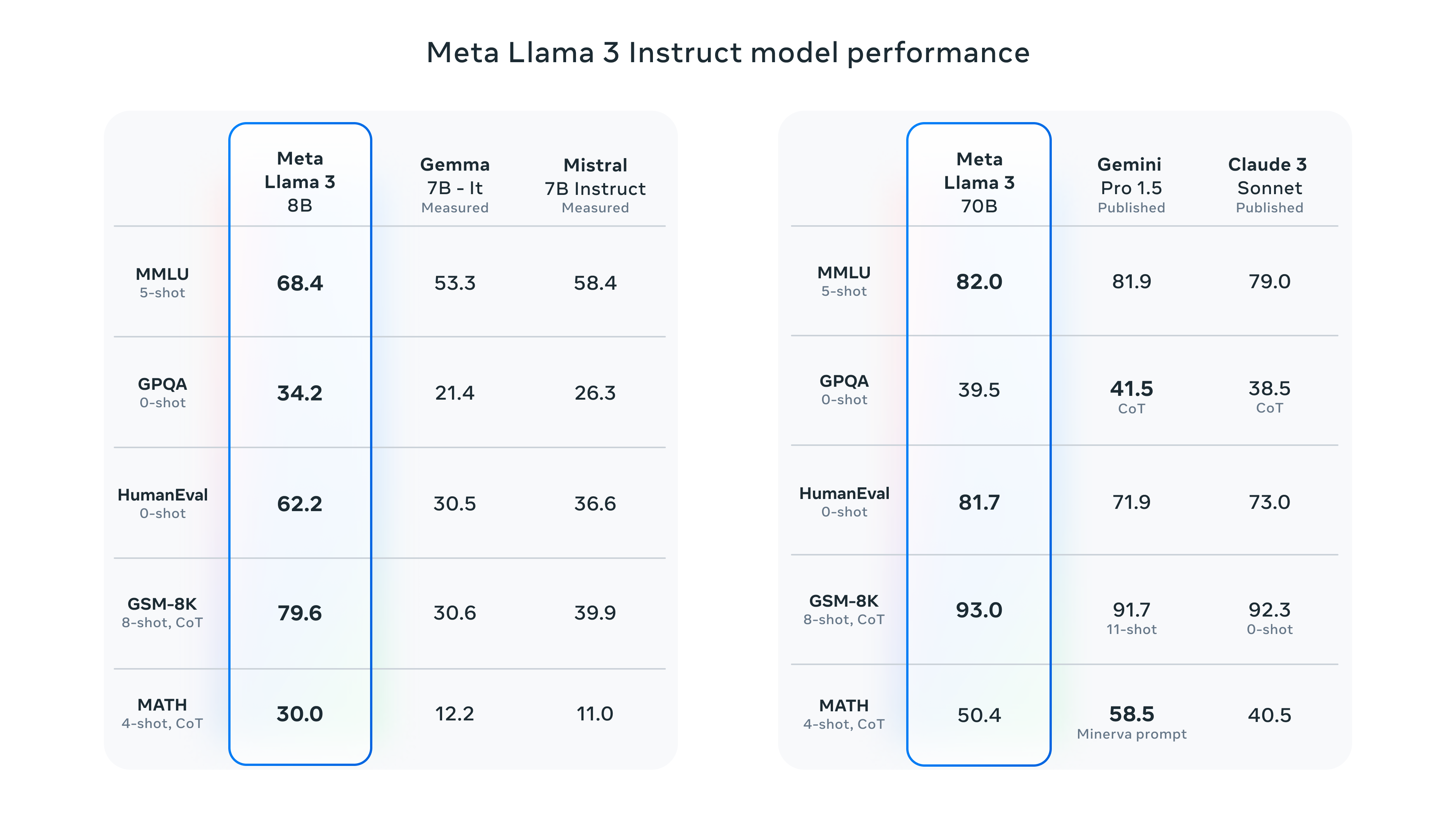
Impressively, it’s evaluation process goes beyond the standard benchmarks:
…the evaluation set contains 1,800 prompts that cover 12 key use cases: asking for advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization.
Improved pretraining and post-training processes
One of the key improvements in Meta Llama 3 is the enhancement of both pretraining and post-training processes [1]. These improvements contribute to the overall performance and capabilities of the model.
In terms of pretraining, Meta has refined the process to provide better initial language understanding and context to the model [1]. Specifically, the developers leveraged a technique to enable optimal data mix for optimizing the use of training compute, and predicting training performance on large models before any training happened. This enables Llama 3 to have a stronger foundation for strong performance across various tasks.
The post-training processes in Llama 3 have also been significantly improved [2]. These enhancements result in lower false refusal rates, improved response alignment, and increased diversity in model answers [2]. By refining the post-training processes, Meta has ensured that Llama 3 produces more accurate and varied responses, enhancing the overall end-user experience.
Ability to handle multi-step tasks effortlessly
With its enhanced scalability and performance, Meta Llama 3 is capable of handling multi-step tasks effortlessly [2]. This means that the model can understand and execute complex instructions that require multiple steps. Whether it is reasoning, code generation, or following detailed instructions, Llama 3 excels in these areas [2].
The 8B parameter model of Llama 3 strikes a balance between performance and computational efficiency, making it suitable for a wide range of applications and deployment scenarios [4]. Despite its relatively smaller size compared to the 70B model, the 8B model delivers exceptional performance across various tasks [4]. This versatility makes it a popular choice for many users.
Reasoning and logical explanations
One of the key capabilities of Llama 3 is its improved reasoning ability. With its advanced algorithms and training techniques, Llama 3 can provide logical explanations for various queries and tasks. Whether it's solving complex problems or providing step-by-step reasoning behind its answers, Llama 3 excels in delivering accurate and logical explanations[2].
Specifically, learning from preference rankings via proximal policy optimization(PPO) and direct preference optimization(DPO) greatly improved the performance of Llama 3 on reasoning tasks.
We found that if you ask a model a reasoning question that it struggles to answer, the model will sometimes produce the right reasoning trace: The model knows how to produce the right answer, but it does not know how to select it. Training on preference rankings enables the model to learn how to select it.
In addition, Llama 3 offers a range of state-of-the-art capabilities including, code generation capabilities, and instruction understanding and following make it a versatile language model that can be utilized by individuals, creators, researchers, and businesses of all sizes[2].
Adherence to responsible AI practices
Meta is committed to responsible AI practices, and Llama 3 reflects this commitment with what they called a “system-level approach”. The development of Llama 3 incorporates ethical considerations and guidelines, such as adding the input and output safeguard and including model-level mitigation strategies.
By adhering to responsible AI practices, Meta aims to mitigate potential risks associated with language models and promote the responsible use of AI technologies [1].

Future Directions of Llama 3

While Llama 3 already boasts impressive capabilities, Meta acknowledges that there is always room for improvement [11]. The company actively seeks feedback from users and the AI research community to identify areas where Llama 3 can be refined and enhanced.
In addition, their largest models are over 400B parameters and are still in training. And there will be multiple models released with new capabilities including multimodality, the ability to converse in multiple languages, a much longer context window, and stronger overall capabilities.
Overall, Meta Llama 3 introduces enhanced scalability and performance compared to its predecessor, Llama 2. The introduction of the 8B and 70B parameter models, along with improvements in pretraining and post-training processes, allows Llama 3 to out-perform most models on the market today across various tasks. These advancements make Llama 3 a powerful tool for various applications and contribute to its position as a state-of-the-art LLM model [1][2][4].
Additionally, responsible AI practices are a key focus for Meta and Llama 3. As AI technologies become more prevalent in society, it is crucial to ensure that they are developed and deployed ethically. Llama 3 already incorporates responsible AI practices, but Meta is committed to continuously improving and refining these practices. This includes addressing issues such as bias, fairness, and transparency in the model's responses and behavior [3].
🛠️✨ Happy practicing and happy building! 🚀🌟
Thanks for reading our newsletter. You can follow us here: Angelina Linkedin or Twitter and Mehdi Linkedin or Twitter.
Source of images/quotes:
🗞️Paper: Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models https://arxiv.org/pdf/2402.19427.pdf
📚 Also if you'd like to learn more about RAG systems, check out our book on the RAG system:
References:
Introducing Meta Llama 3: The most capable openly available LLM to date
Meta Llama 3: A Powerful, Responsible and Accessible LLM for ... - LinkedIn
Llama-3-8B and Llama-3-70B: A Quick Look at Meta's Open Source LLM ...
Meta Launches Llama 3 Model, But How Powerful Is It? - FavTutor
GitHub - meta-llama/llama3: The official Meta Llama 3 GitHub site
Meta Unveils Llama 3 — 10 Key Facts About The Advanced LLM - Forbes
Everything To Know About Meta's New Openly Available AI Model - Llama 3
Meta releases new AI assistant powered by Llama 3 model - The Verge
Meta releases its new Llama 3 open-source AI model. Is it enough to ...
Meta's Llama 3 AI Is Smart, But Who Is Going To Profit From It?
Meta AI in 2024: Will Llama 3 Beat GPT-4 & Gemini? Techopedia