

LongRAG: Combining RAG with Long-Context LLMs for Enhanced Performance
LongRAG: Combining RAG with Long-Context LLMs for Enhanced Performance

Retrieval-Augmented Generation (RAG) methods have emerged as a powerful approach to enhance the capabilities of large language models (LLMs) by incorporating external knowledge retrieved from vast corpora.
This technique is particularly beneficial for open-domain question answering, where detailed and accurate responses are crucial. By leveraging external information, RAG systems can overcome the limitations of relying solely on the parametric knowledge embedded in LLMs, making them more effective in handling complex queries.
Challenges for RAG
However, a significant challenge in RAG systems is the imbalance between the retriever and reader components.
Traditional frameworks often use short retrieval units, such as 100-word passages, requiring the retriever to sift through large amounts of data. This design burdens the retriever heavily while the reader's task remains relatively simple, leading to inefficiencies and potential semantic incompleteness due to document truncation. This imbalance restricts the overall performance of RAG systems, necessitating a re-evaluation of their design.
LongRAG
To address these challenges, the research team from the University of Waterloo introduced a novel framework called LongRAG. This framework comprises a "long retriever" and a "long reader" component, designed to process longer retrieval units of around 4K tokens each.
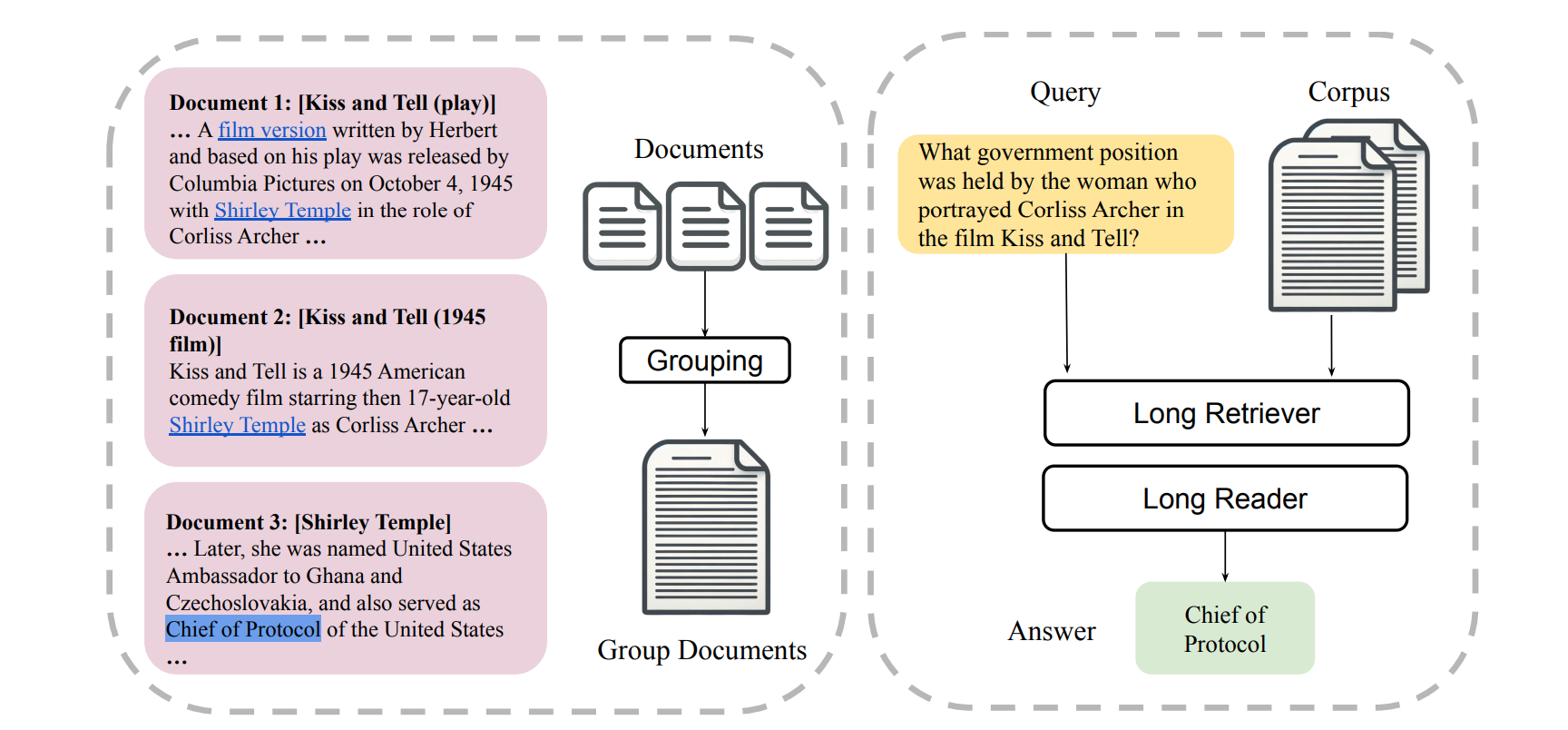
By increasing the size of the retrieval units, LongRAG reduces the number of units from 22 million to 600,000, significantly easing the retriever's workload and improving retrieval scores. This innovative approach allows the retriever to handle more comprehensive information units, enhancing the system's efficiency and accuracy.
How it works
The LongRAG framework operates by grouping related documents into long retrieval units, which the long retriever then processes to identify relevant information.
To extract the final answers, the retriever filters the top 4 to 8 units, concatenated and fed into a long-context LLM, such as Gemini-1.5-Pro or GPT-4o. This method leverages the advanced capabilities of long-context models to process large amounts of text efficiently, ensuring a thorough and accurate extraction of information.
Performance
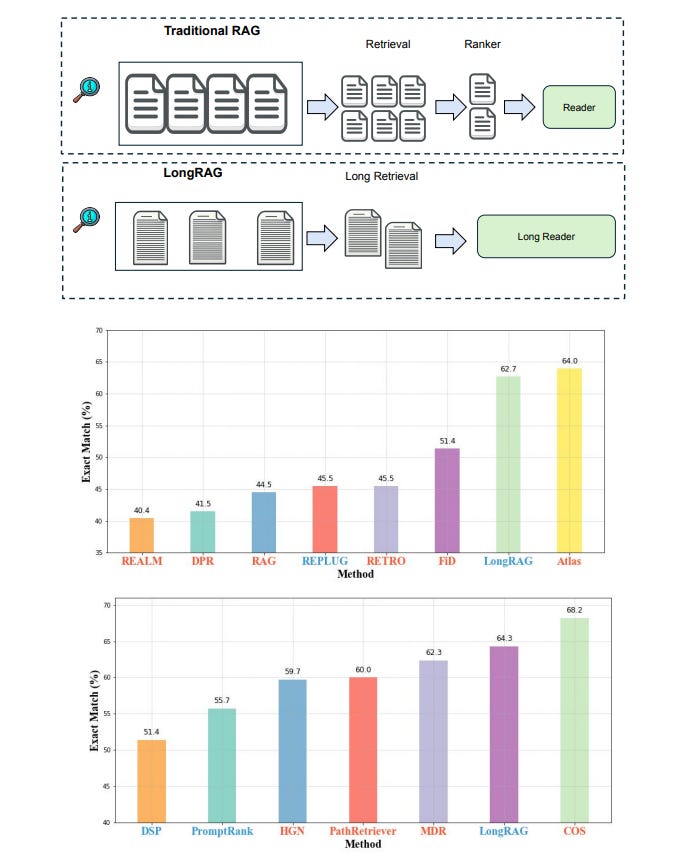
The performance of LongRAG is truly remarkable. On the Natural Questions (NQ) dataset, it achieved an exact match (EM) score of 62.7%, a significant leap forward compared to traditional methods. On the HotpotQA dataset, it reached an EM score of 64.3%. These impressive results demonstrate the effectiveness of LongRAG, matching the performance of state-of-the-art fine-tuned RAG models. The framework reduced the corpus size by up to 30 times and improved the answer recall by approximately 20 percentage points compared to traditional methods, with an answer recall@1 score of 71% on NQ and 72% on HotpotQA.
Keep reading with a 7-day free trial
Subscribe to The MLnotes Newsletter to keep reading this post and get 7 days of free access to the full post archives.